05:00
Lab 3 - Coffee ratings
STA 210 - Spring 2022
The data
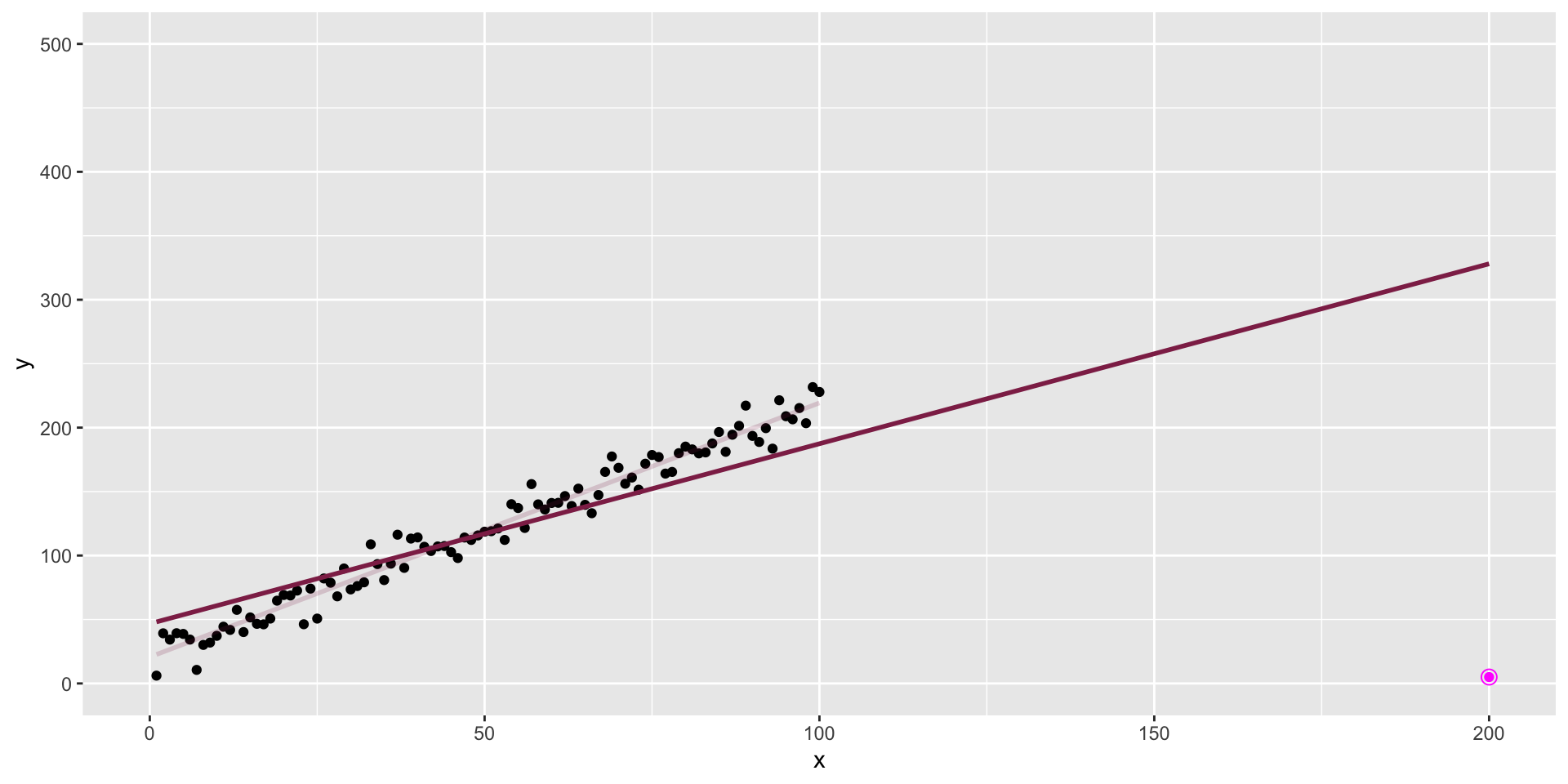
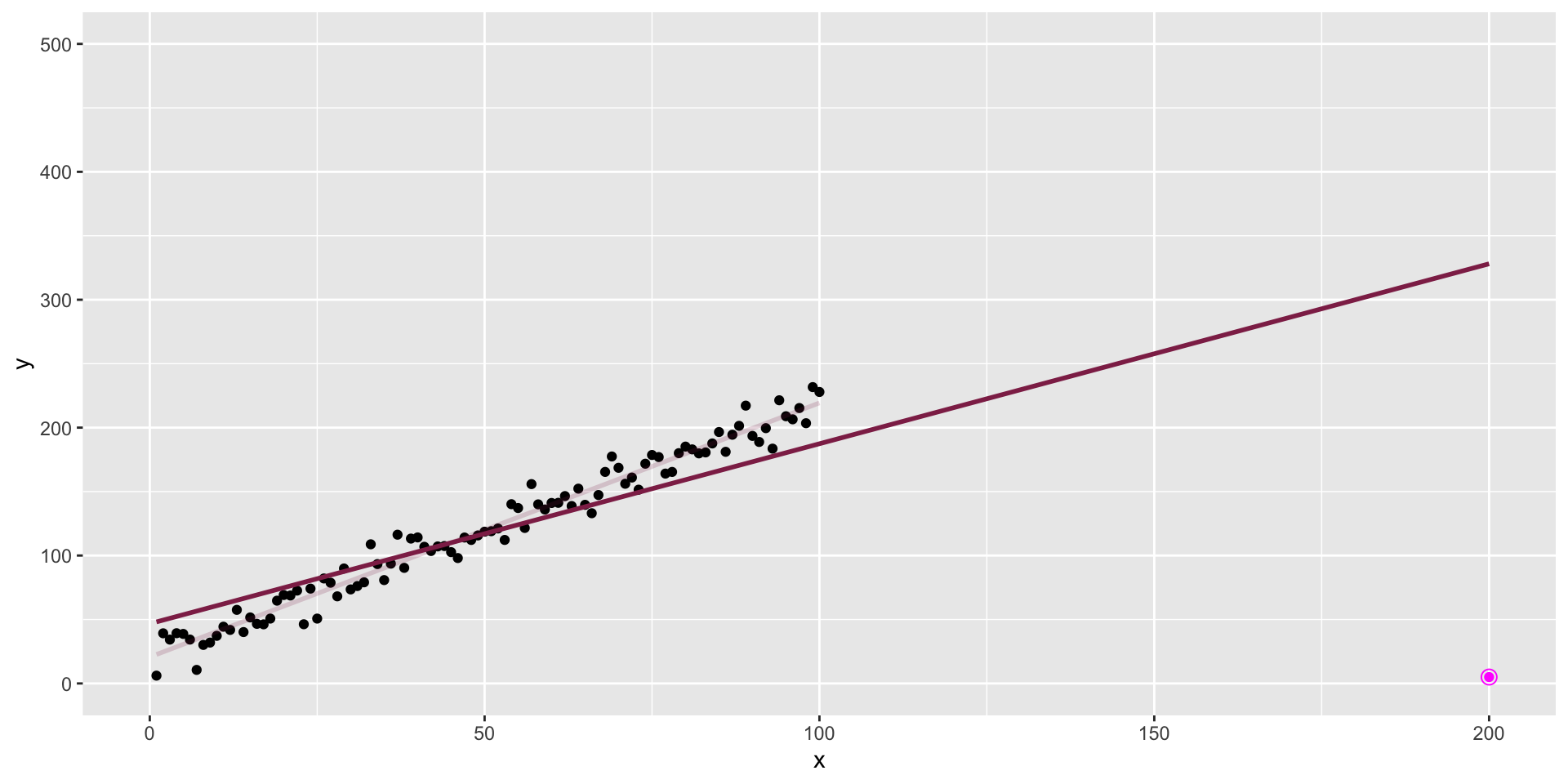
The data + an outlier
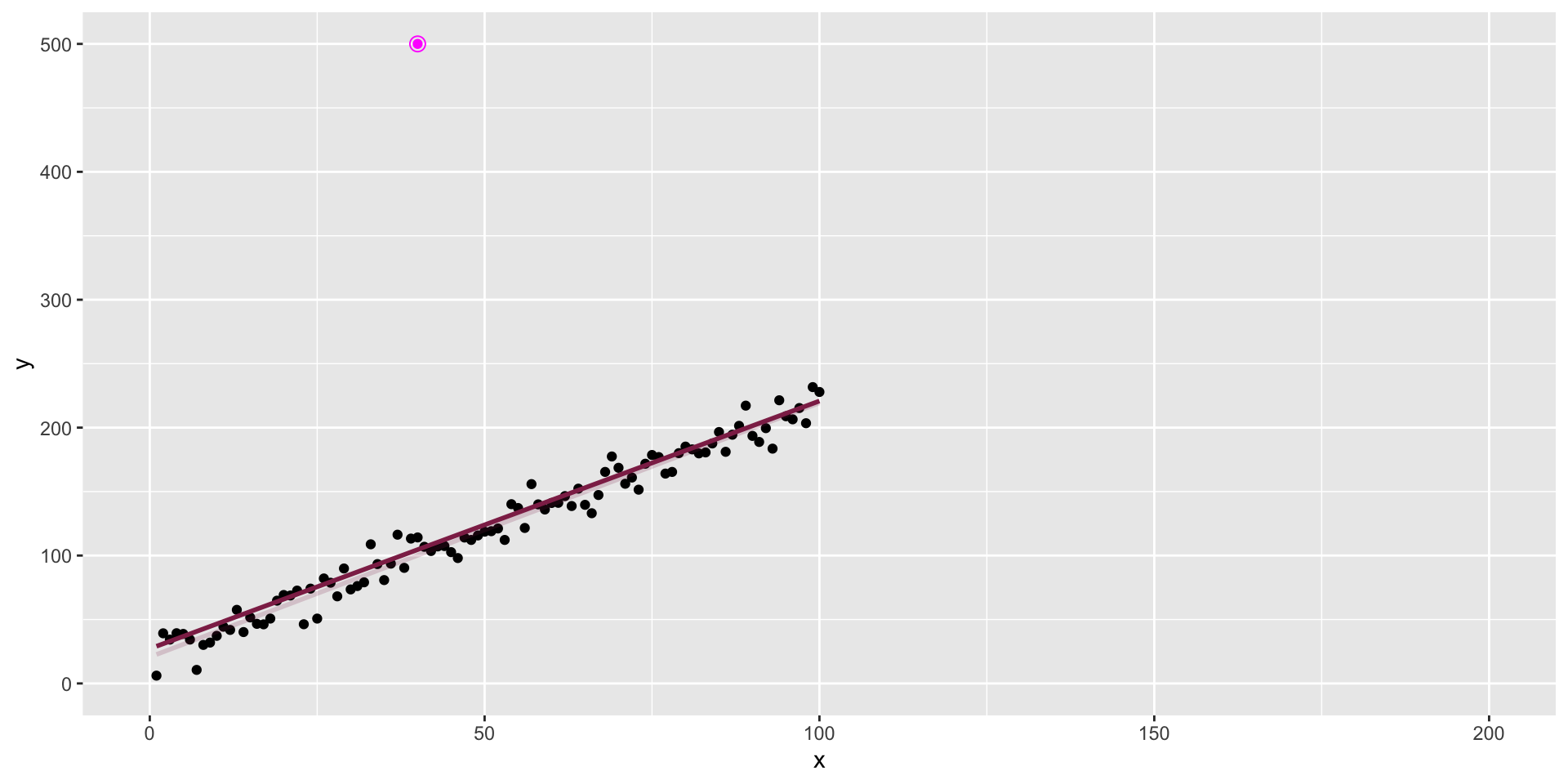
The data + influential point
Influential point
An observation is influential if removing it substantially changes the coefficients of the regression model.
Model diagnostics
Use the augment() function to output statistics that can be used to diagnose the model, along with the predicted values and residuals:
- outcome and predictor variables in the model
.fitted: predicted values.se.fit: standard errors of predicted values.resid: residuals.hat: leverage.sigma: estimate of residual standard deviation when the corresponding observation is dropped from model.cooksd: Cook’s distance.std.resid: standardized residuals