# load packages
library(tidyverse) # for data wrangling and visualization
library(tidymodels) # for modeling
library(usdata) # for the county_2019 dataset
library(openintro) # for the duke_forest dataset
library(scales) # for pretty axis labels
library(glue) # for constructing character strings
library(knitr) # for pretty tables
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_minimal(base_size = 16))SLR: Simulation based-inference
STA 210 - Spring 2022
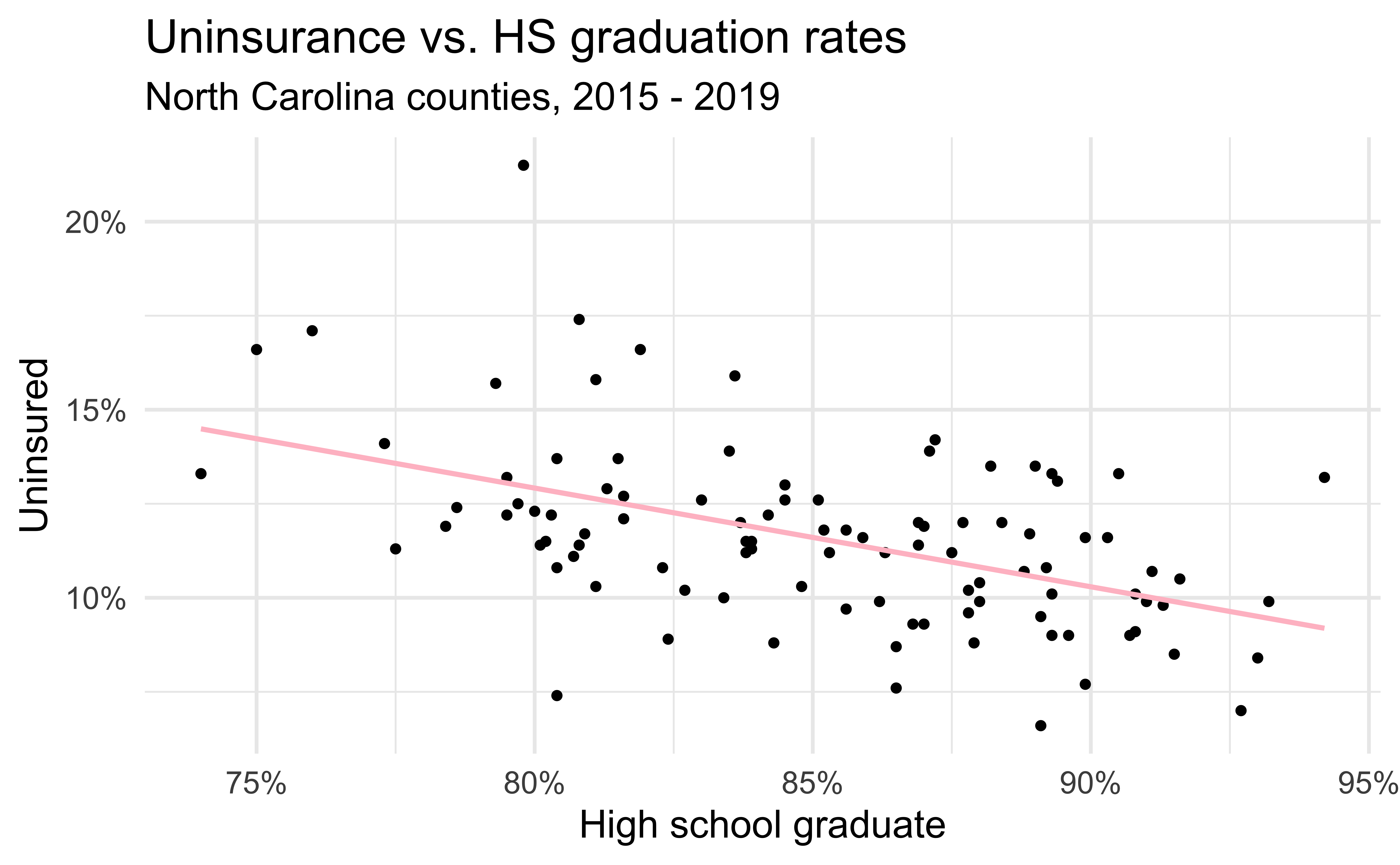
Uninsurance vs. HS graduation in NC
Uninsurance vs. HS graduation in NY
Code
county_2019_ny <- county_2019 %>%
as_tibble() %>%
filter(state == "New York") %>%
select(name, hs_grad, uninsured)
ggplot(county_2019_ny,
aes(x = hs_grad, y = uninsured)) +
geom_point() +
scale_x_continuous(labels = label_percent(scale = 1, accuracy = 1)) +
scale_y_continuous(labels = label_percent(scale = 1, accuracy = 1)) +
labs(
x = "High school graduate", y = "Uninsured",
title = "Uninsurance vs. HS graduation rates",
subtitle = "New York counties, 2015 - 2019"
) +
geom_smooth(method = "lm", se = FALSE, color = "pink")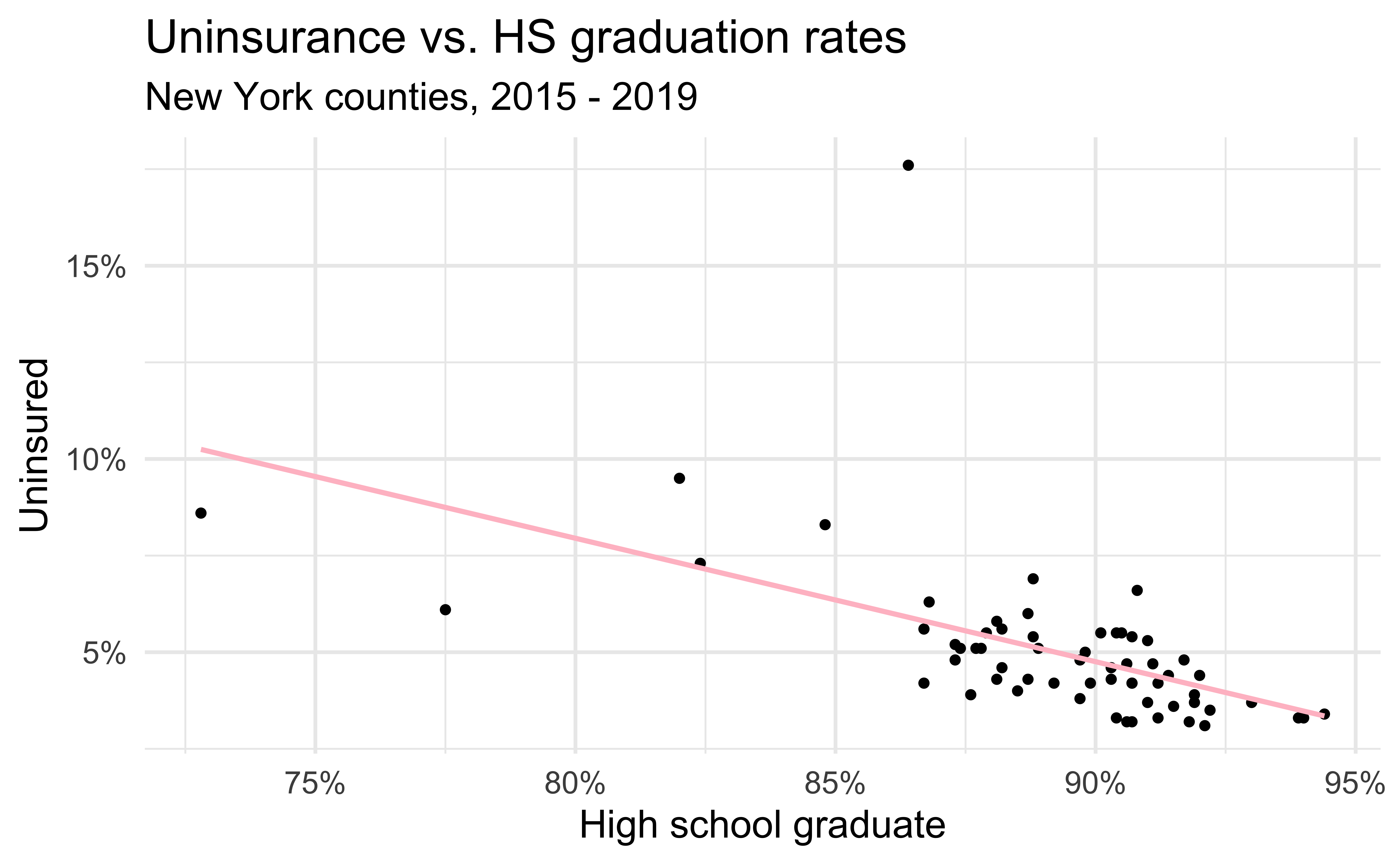
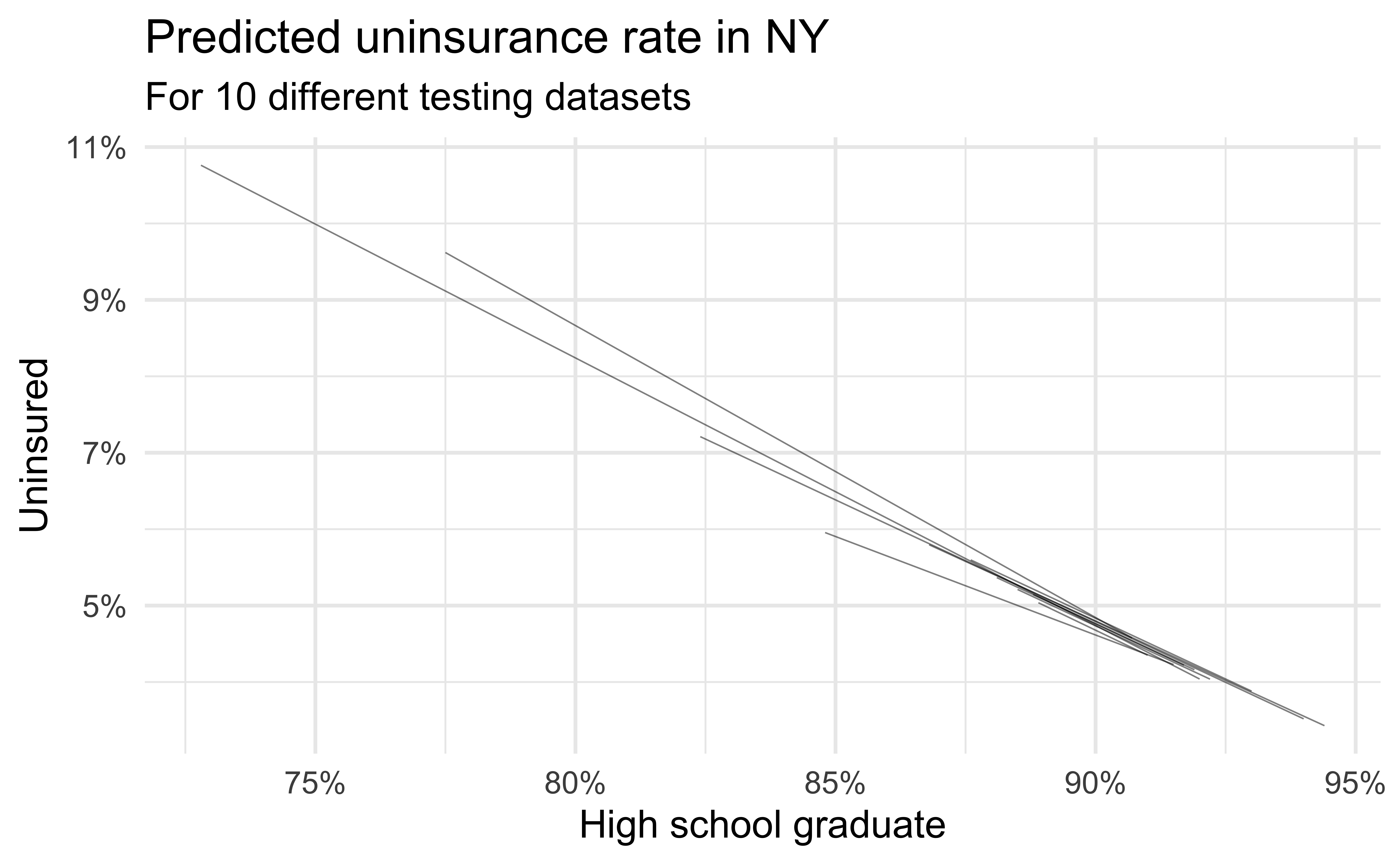
Data splitting
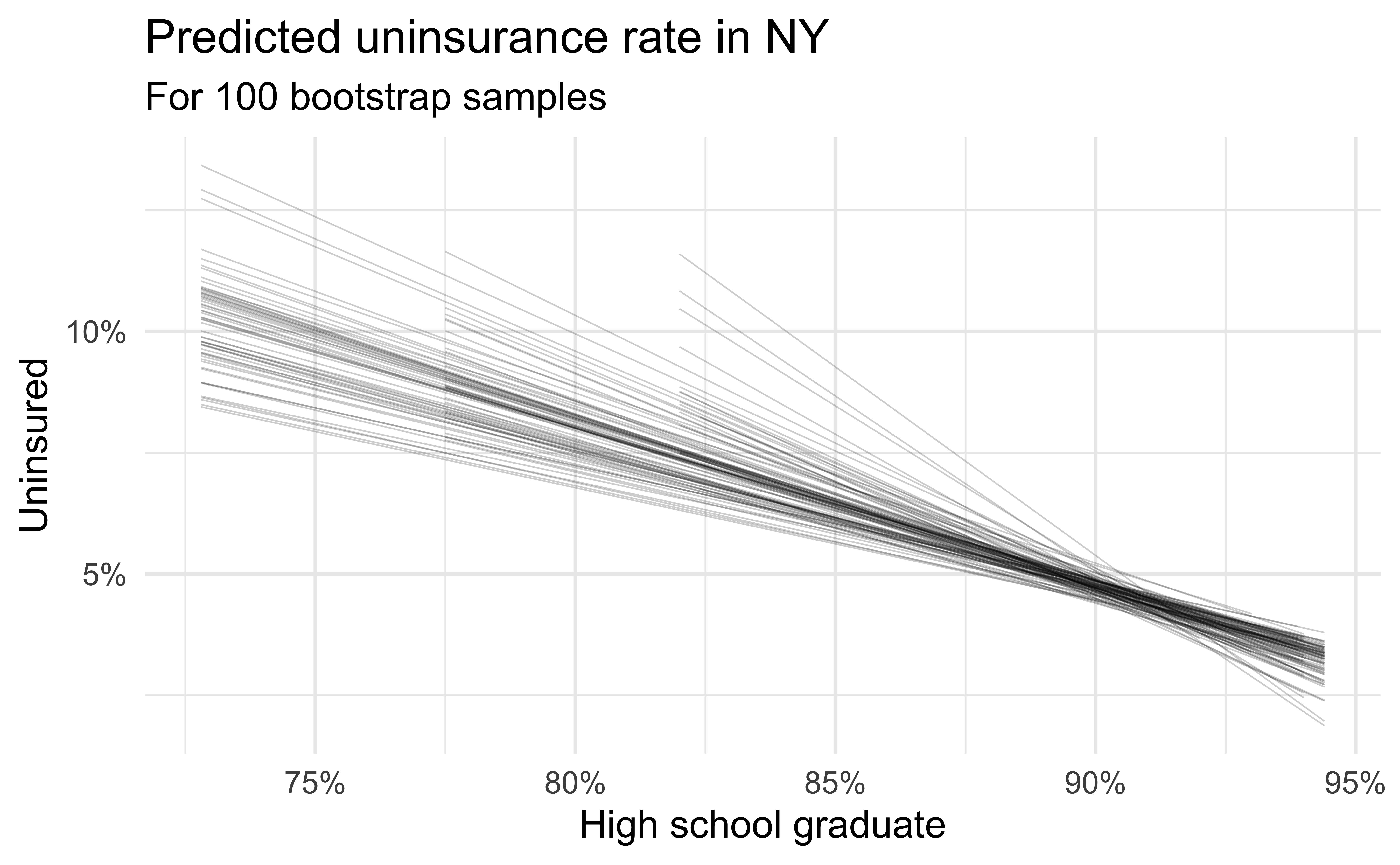
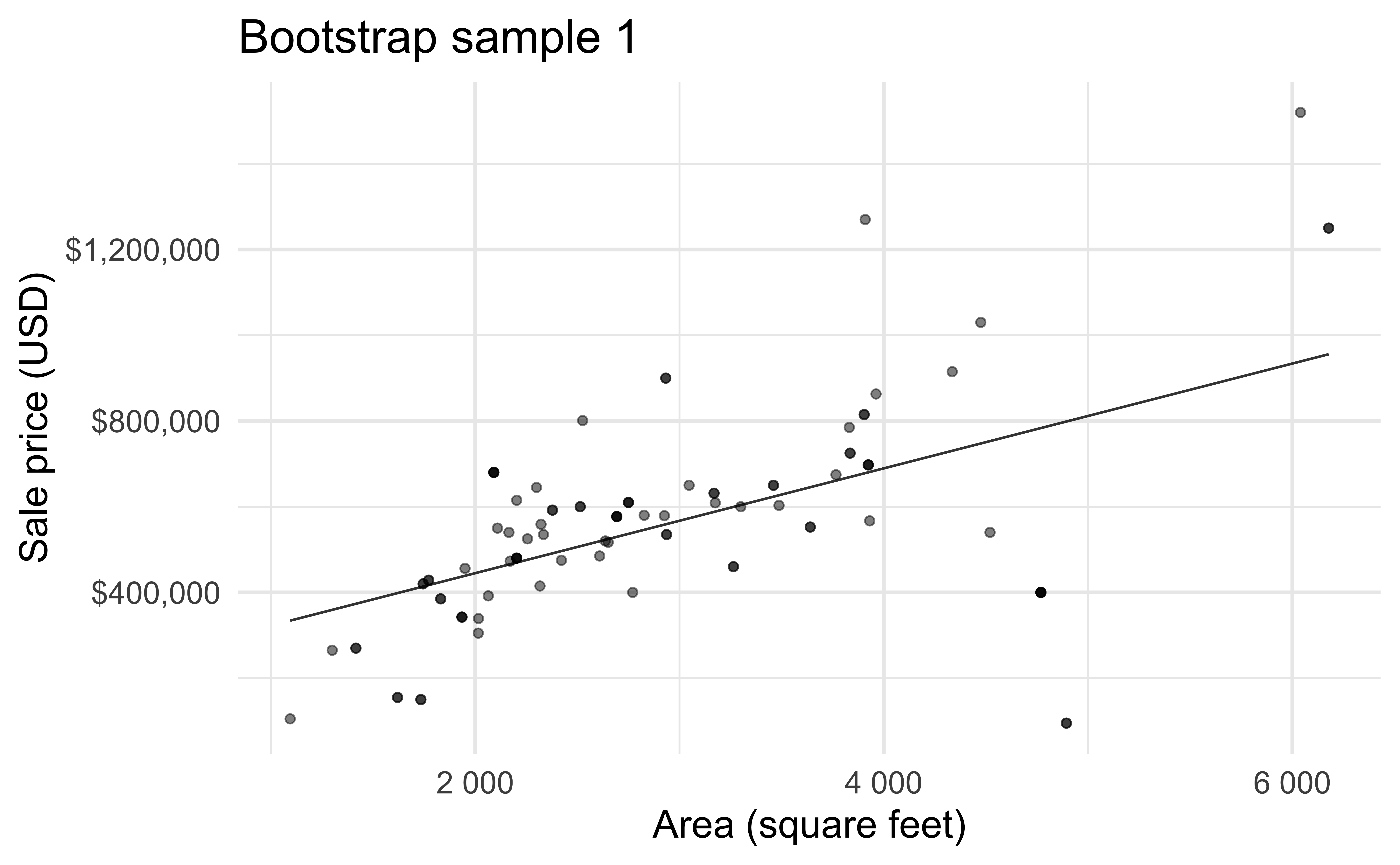
Bootstrapping
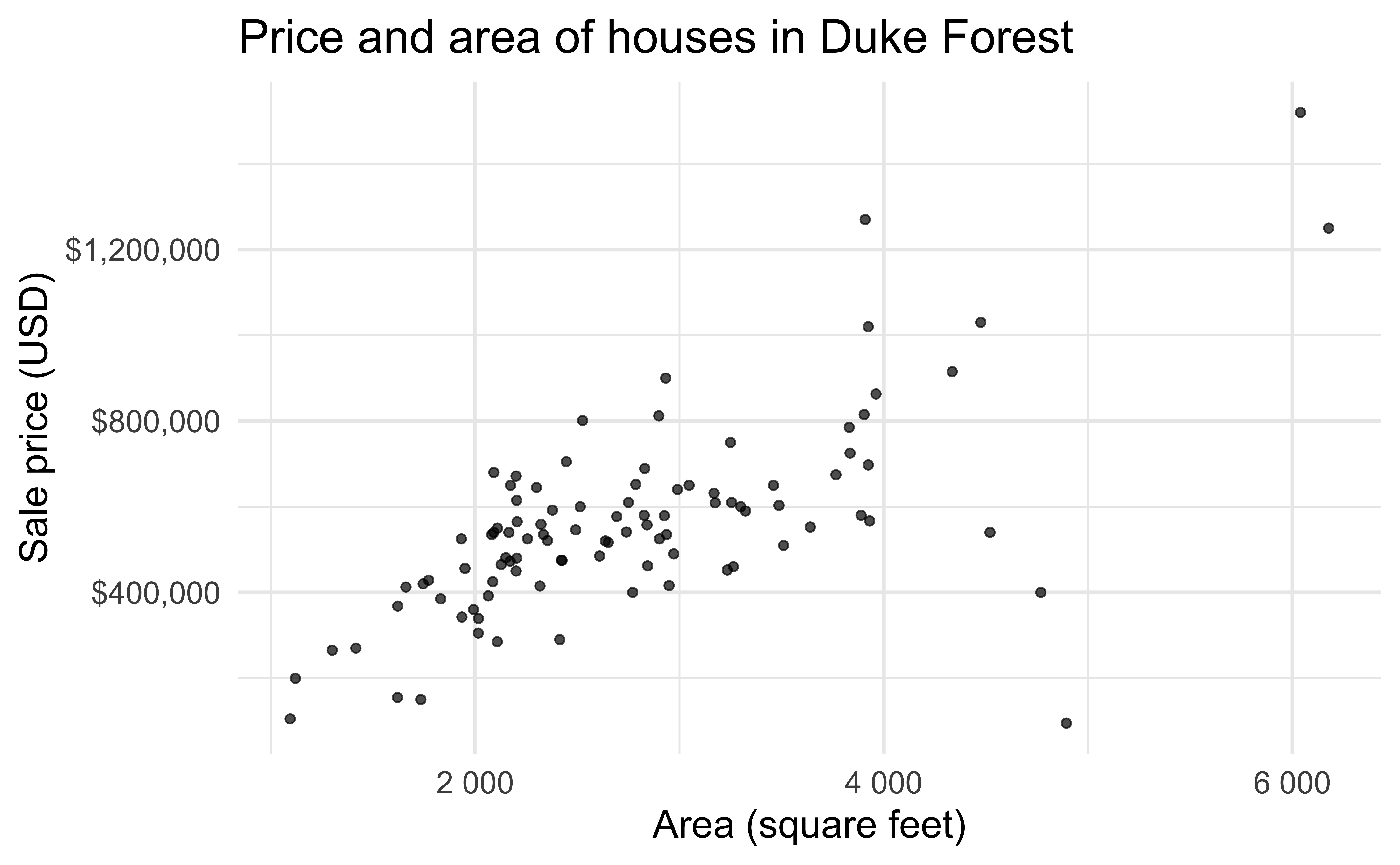
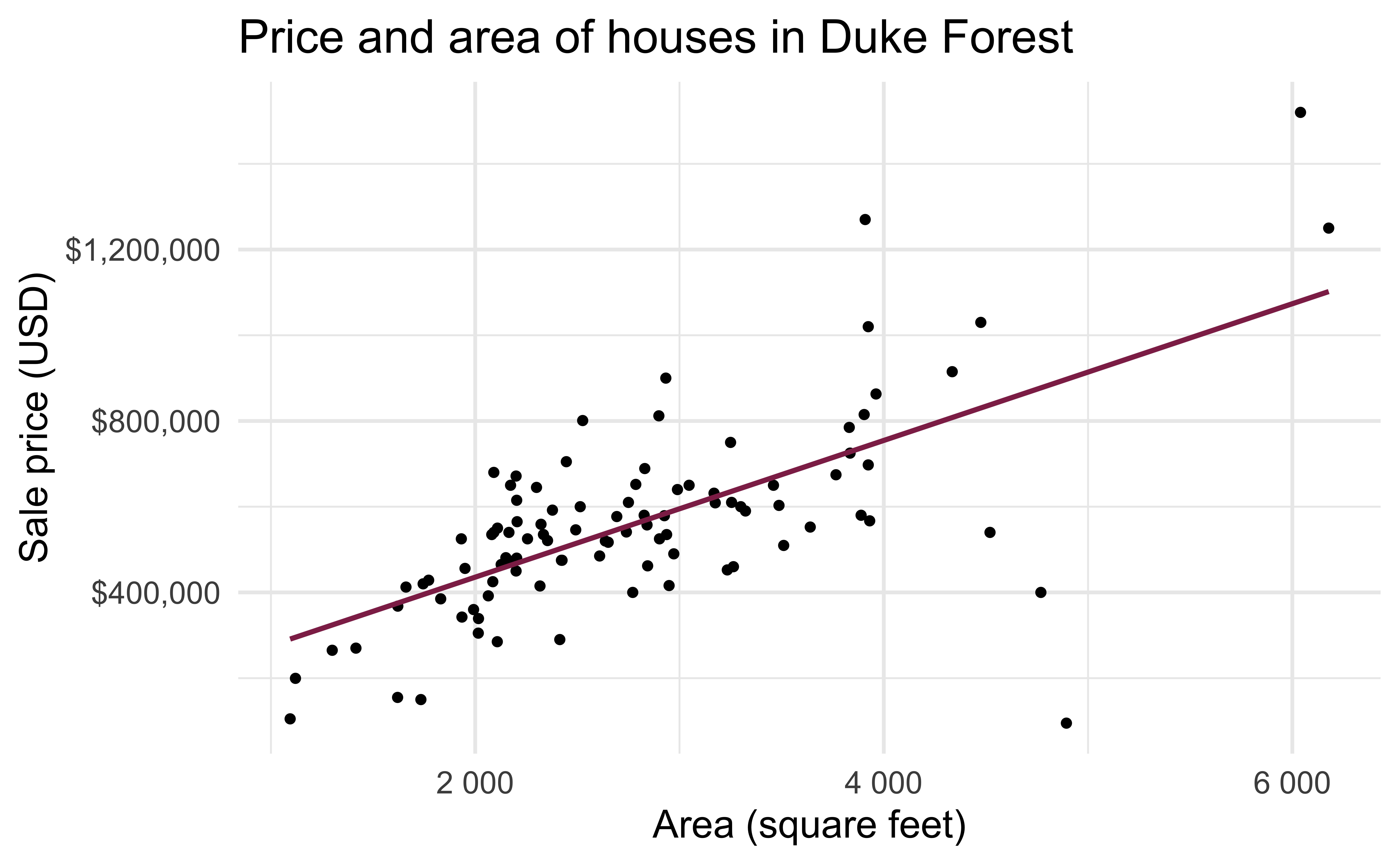
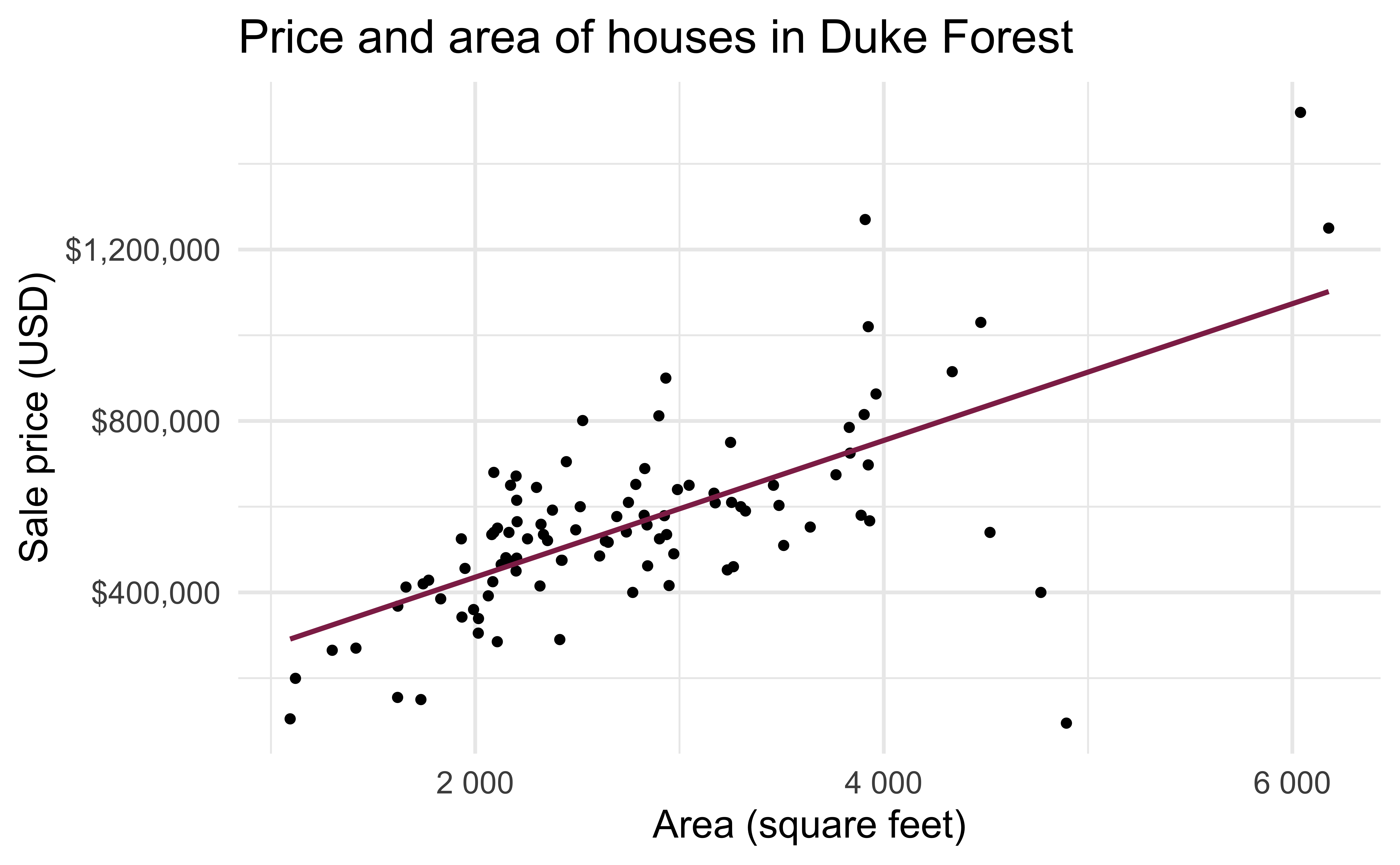
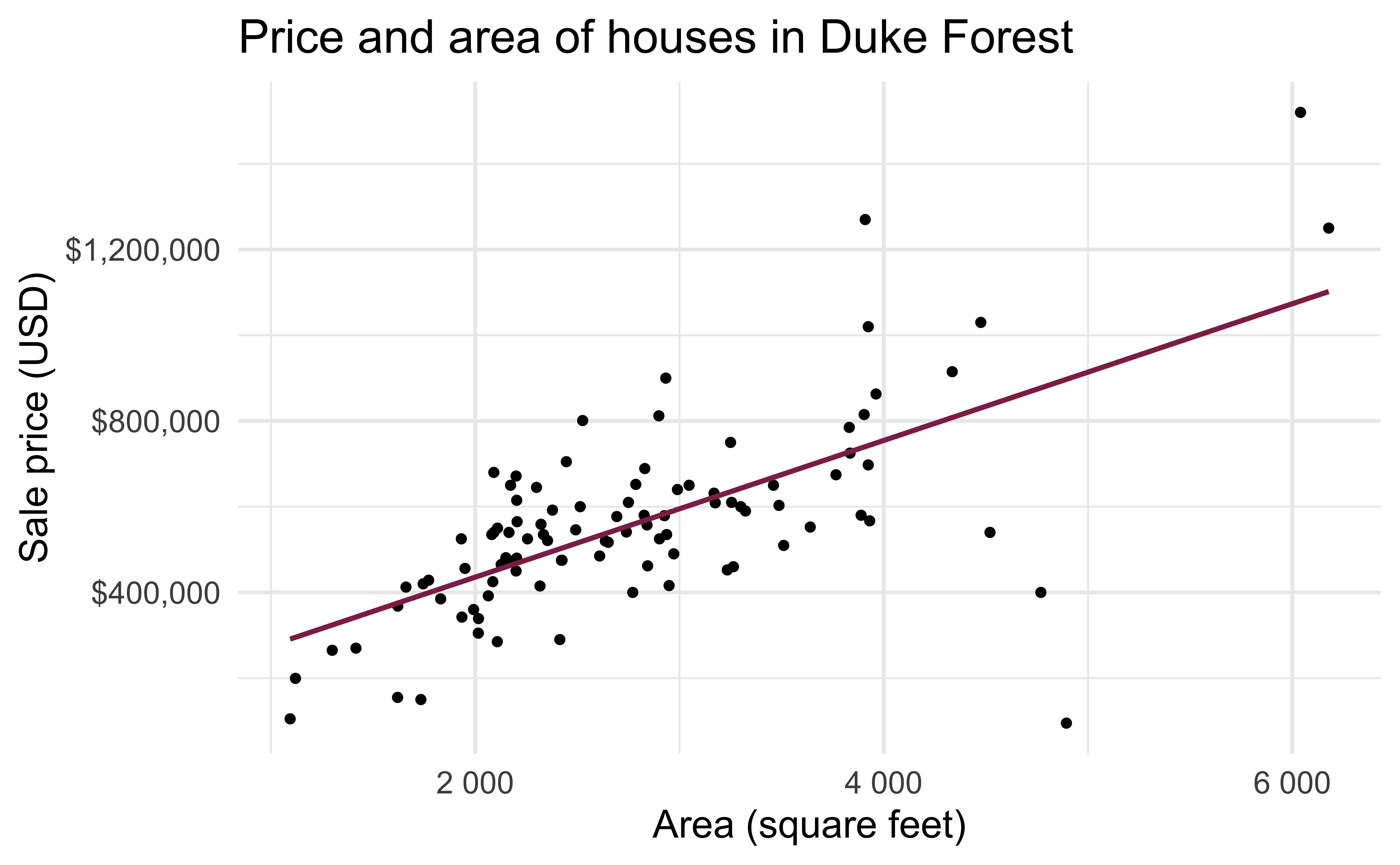
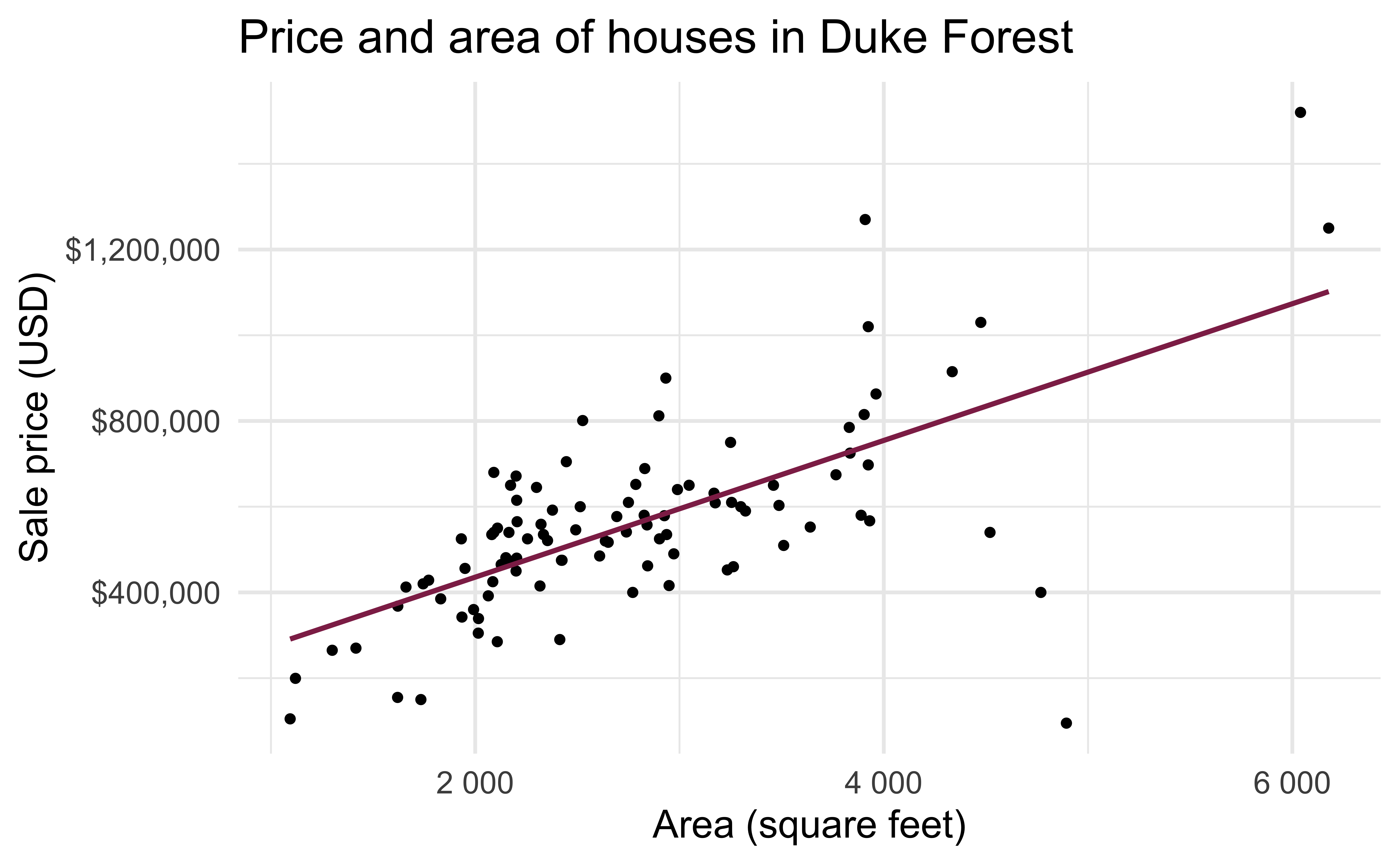
Data: Sale prices of houses in Duke Forest
- Data on houses that were sold in the Duke Forest neighborhood of Durham, NC around November 2020
- Scraped from Zillow
- Source:
openintro::duke_forest

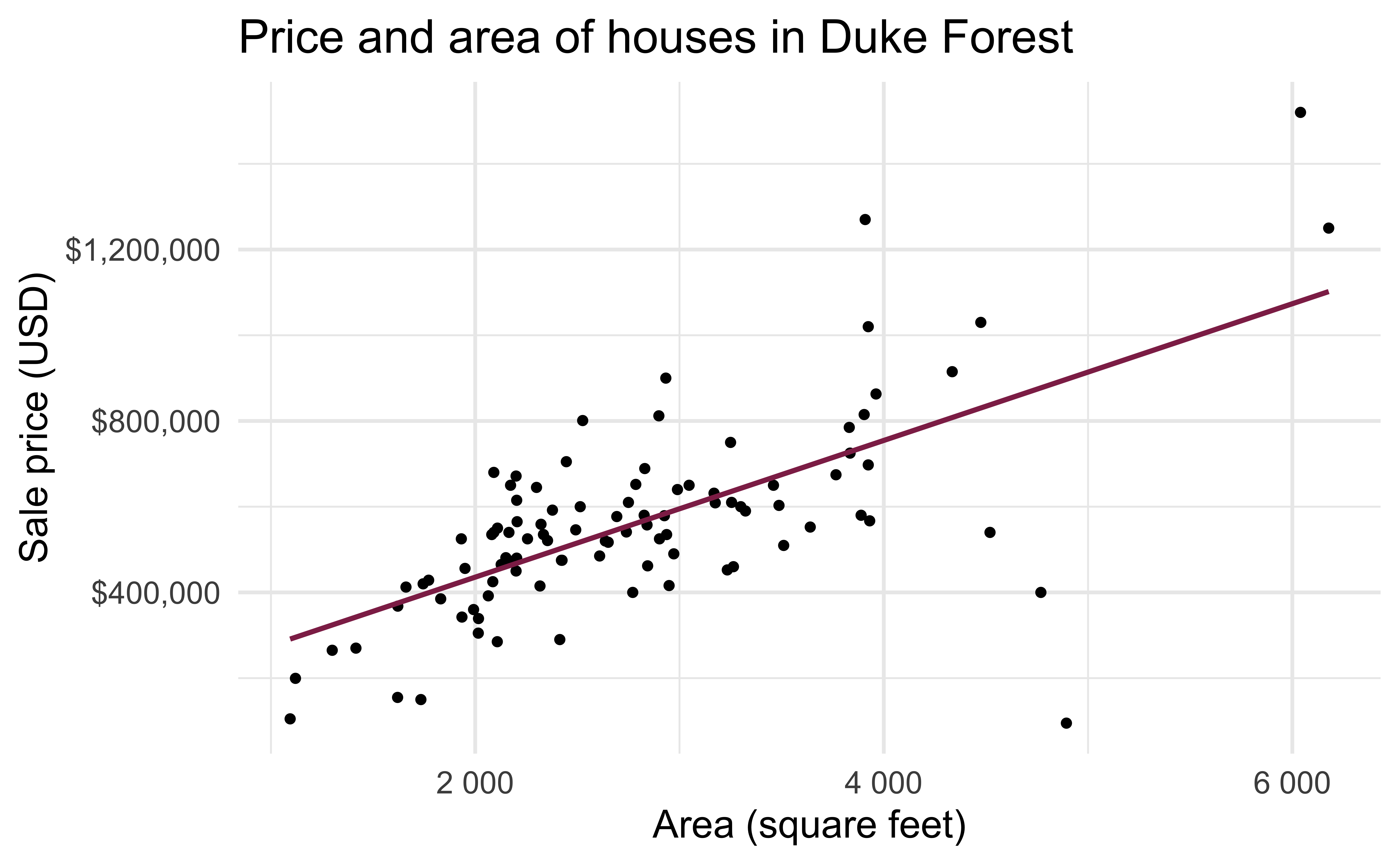
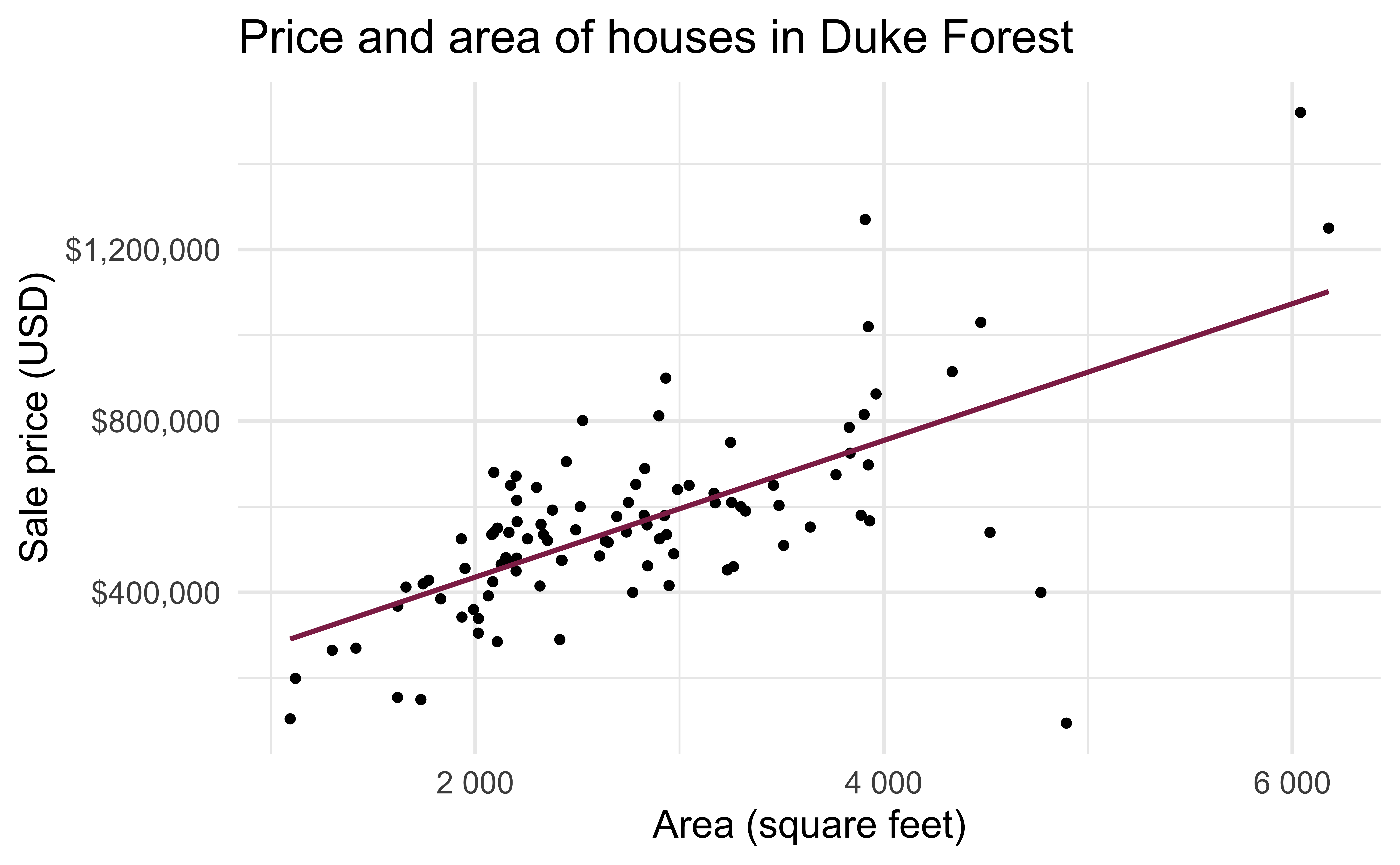
Exploratory analysis
Bootstrap sample 1
Bootstrap sample 2
Bootstrap sample 3

Bootstrap sample 4
Bootstrap sample 5
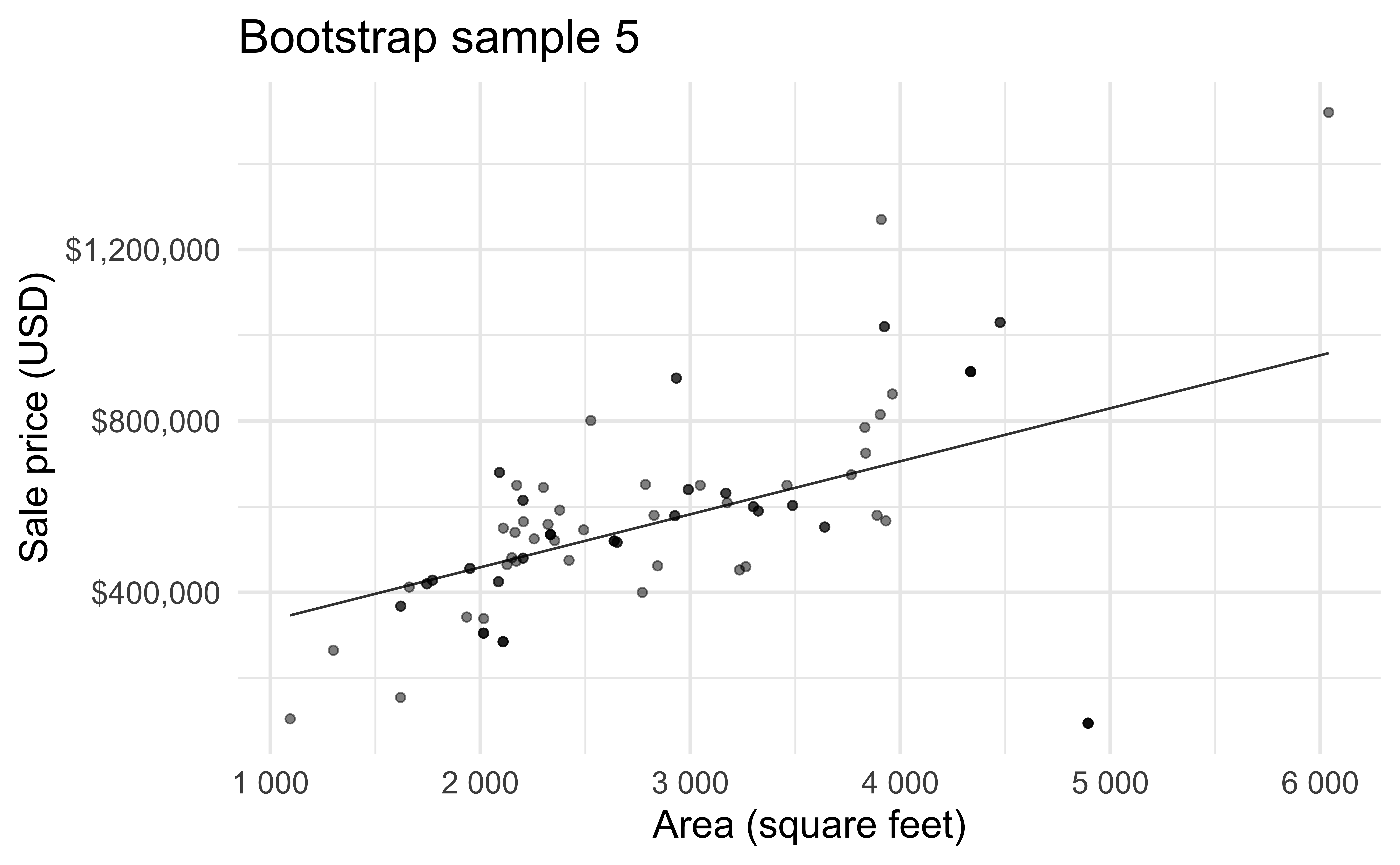
so on and so forth…
Bootstrap samples 1 - 5
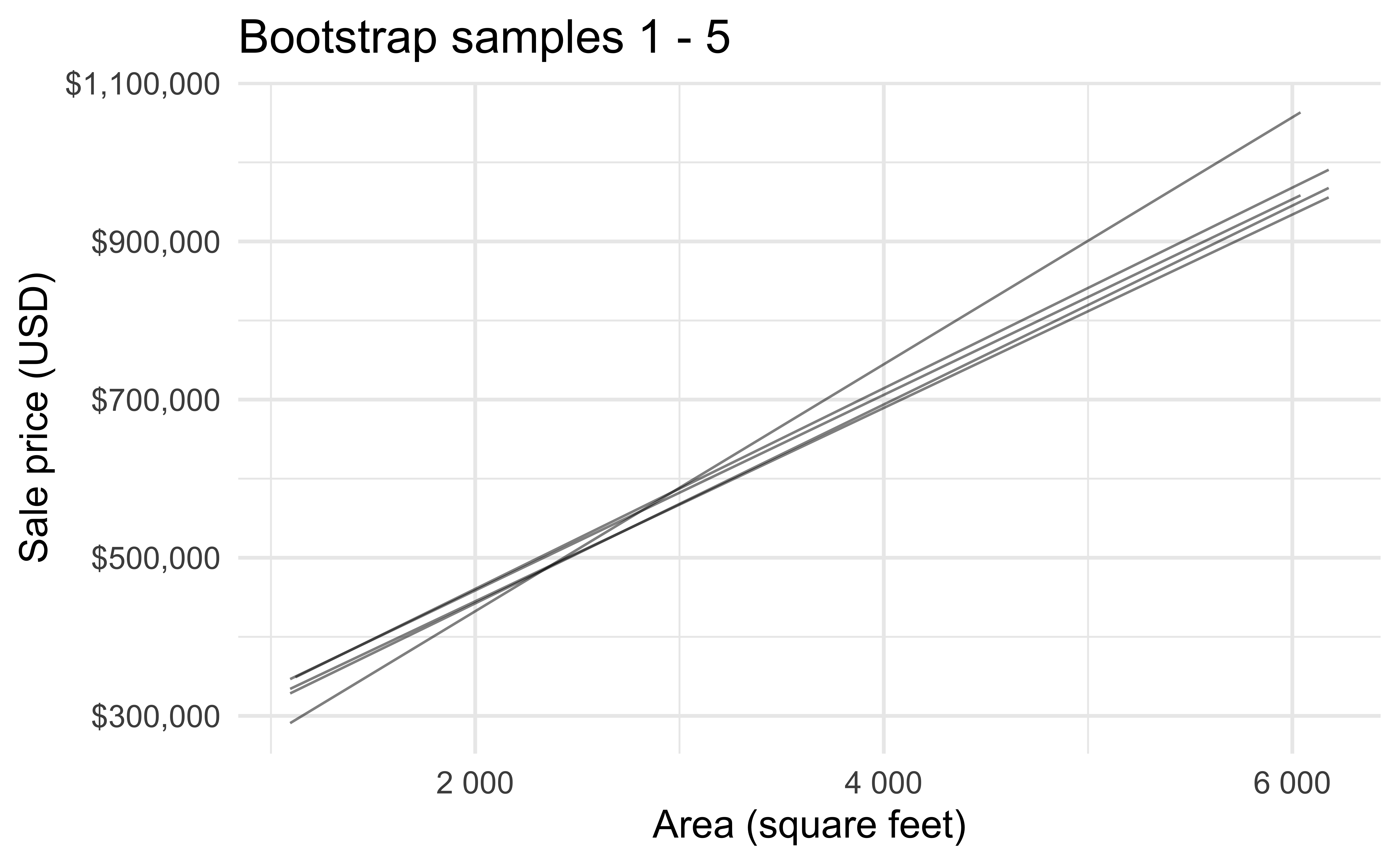
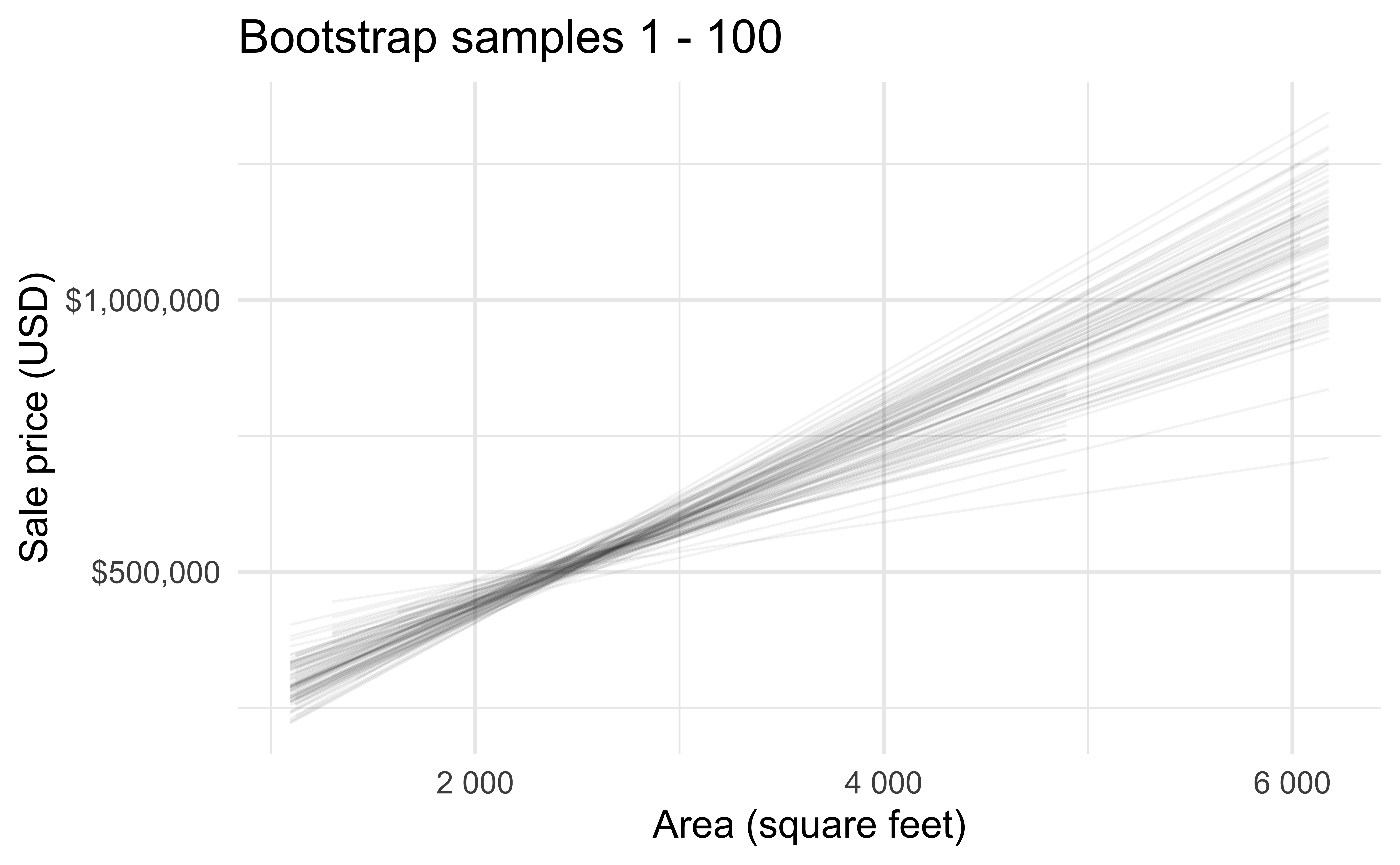
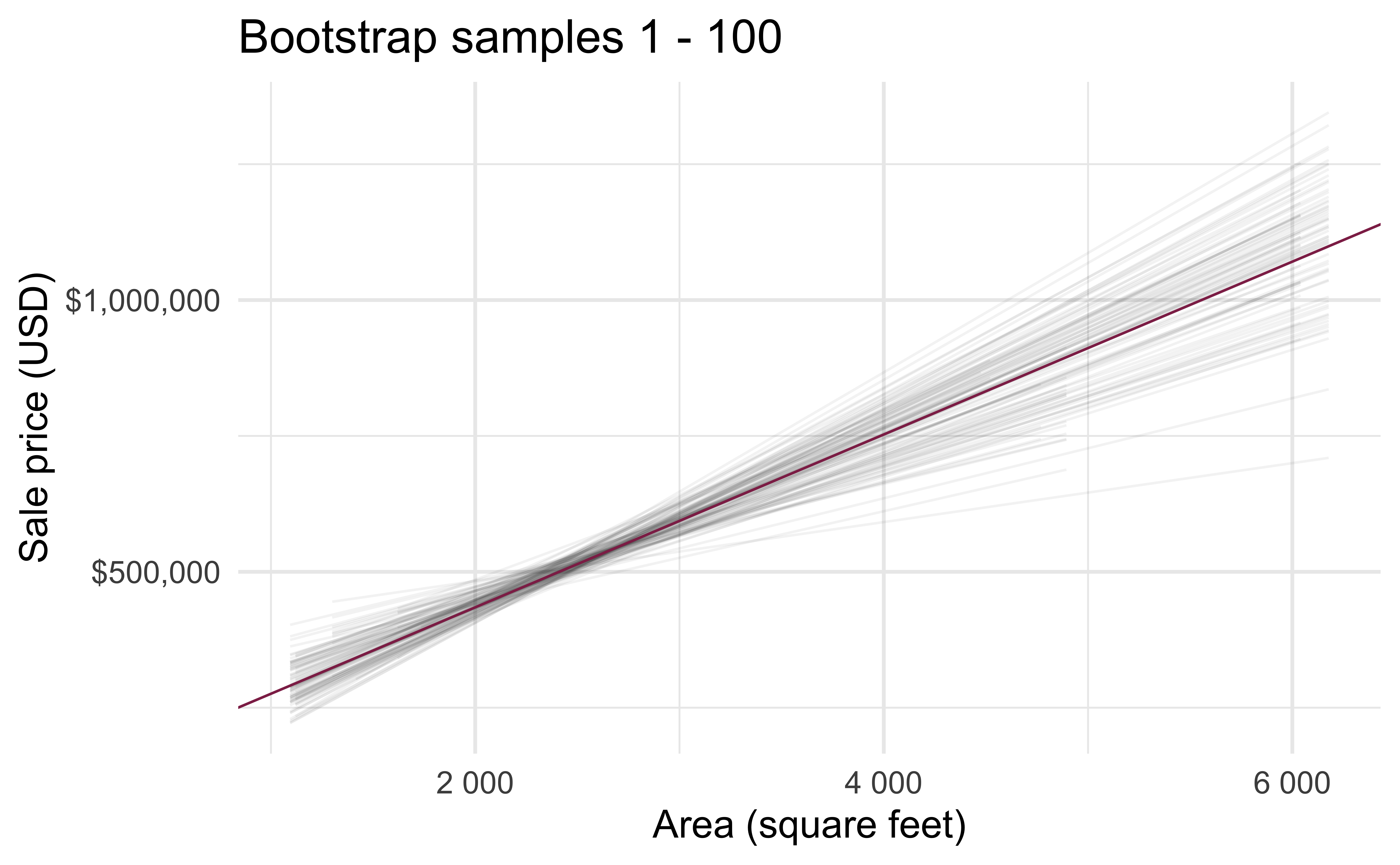
Bootstrap samples 1 - 100
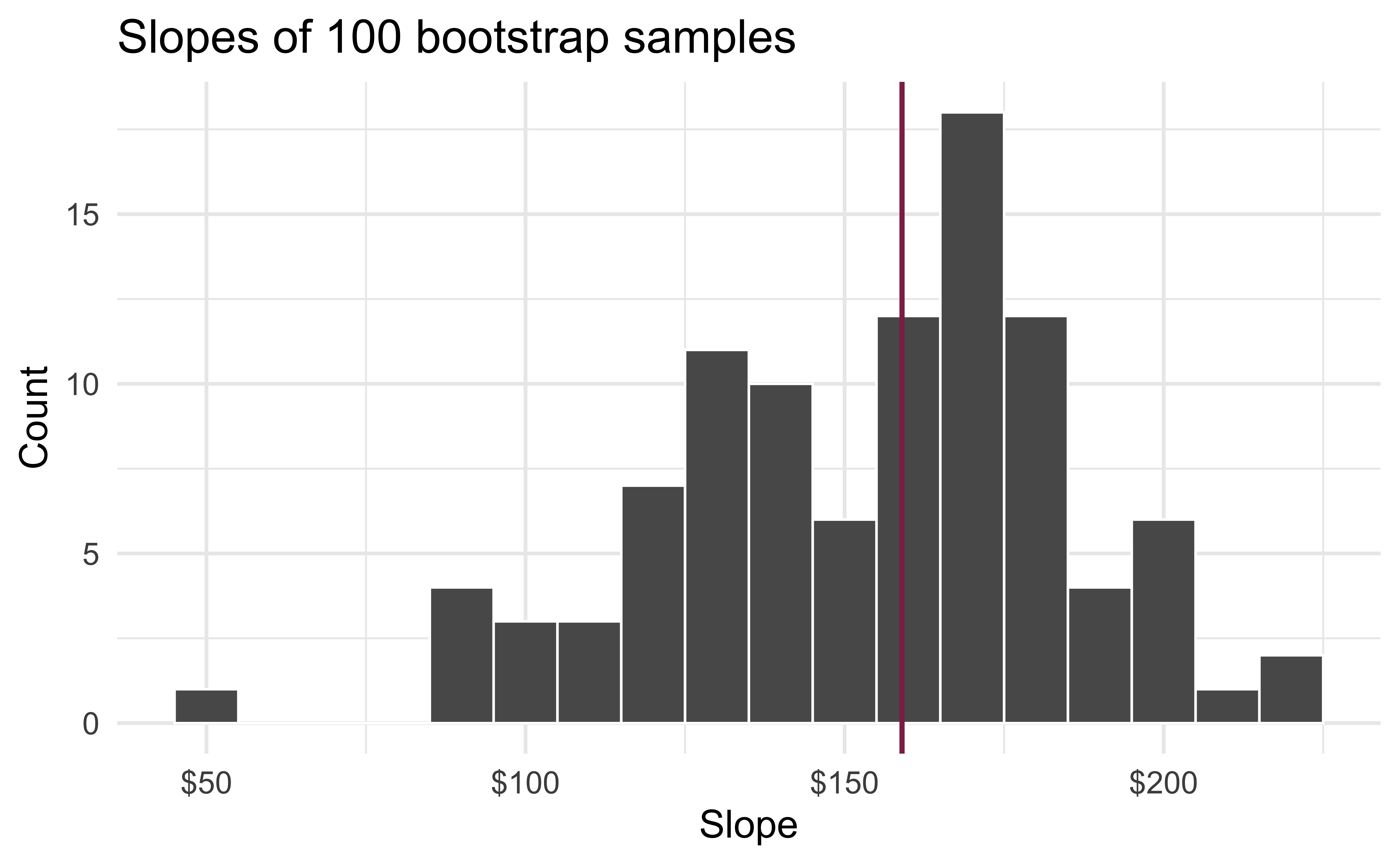
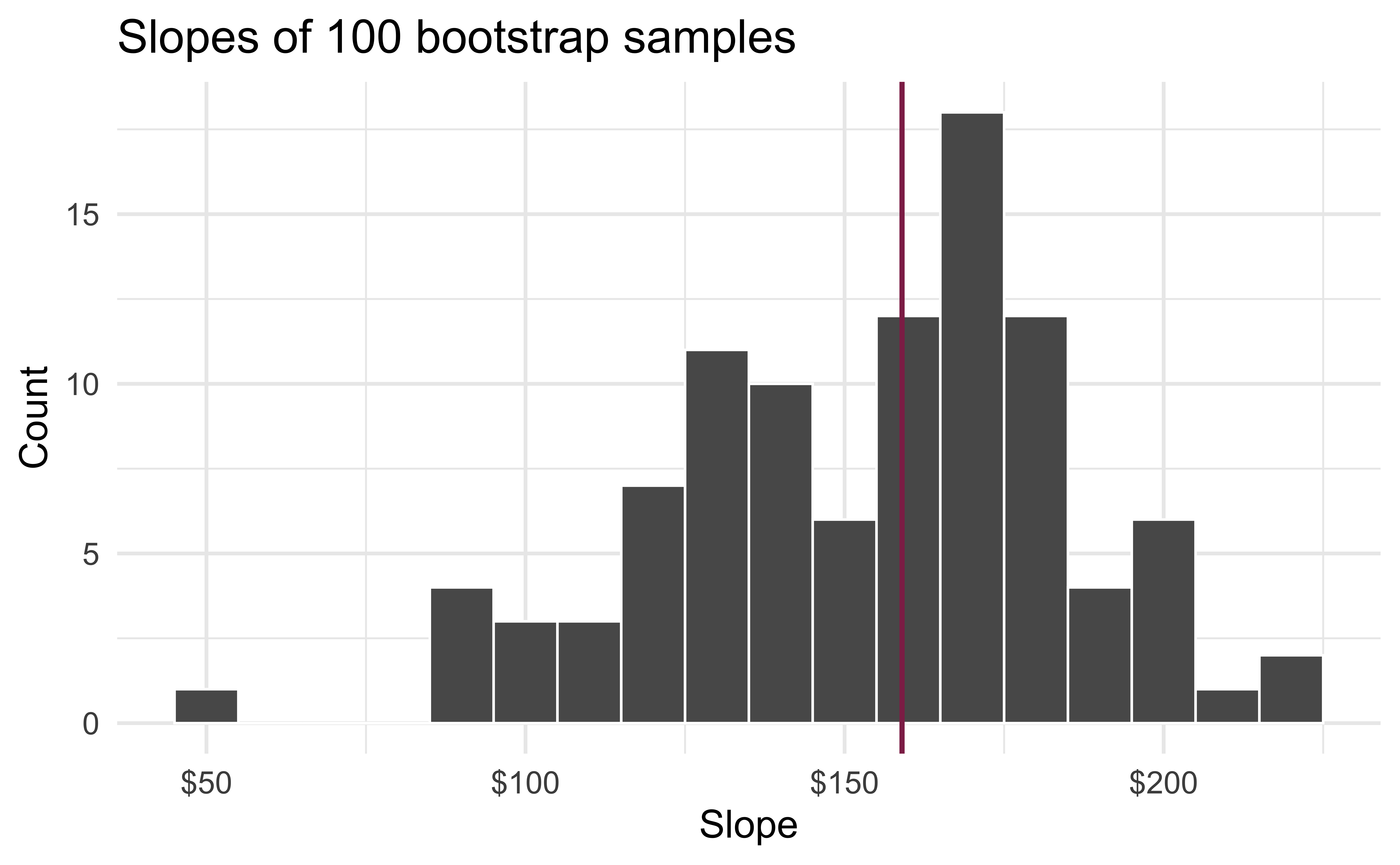
Slopes of bootstrap samples
Fill in the blank: For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $159, give or take ___ dollars.
Slopes of bootstrap samples
Fill in the blank: For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $159, give or take ___ dollars.
Confidence level
How confident are you that the true slope is between $0 and $250? How about $150 and $170? How about $90 and $210?
95% confidence interval
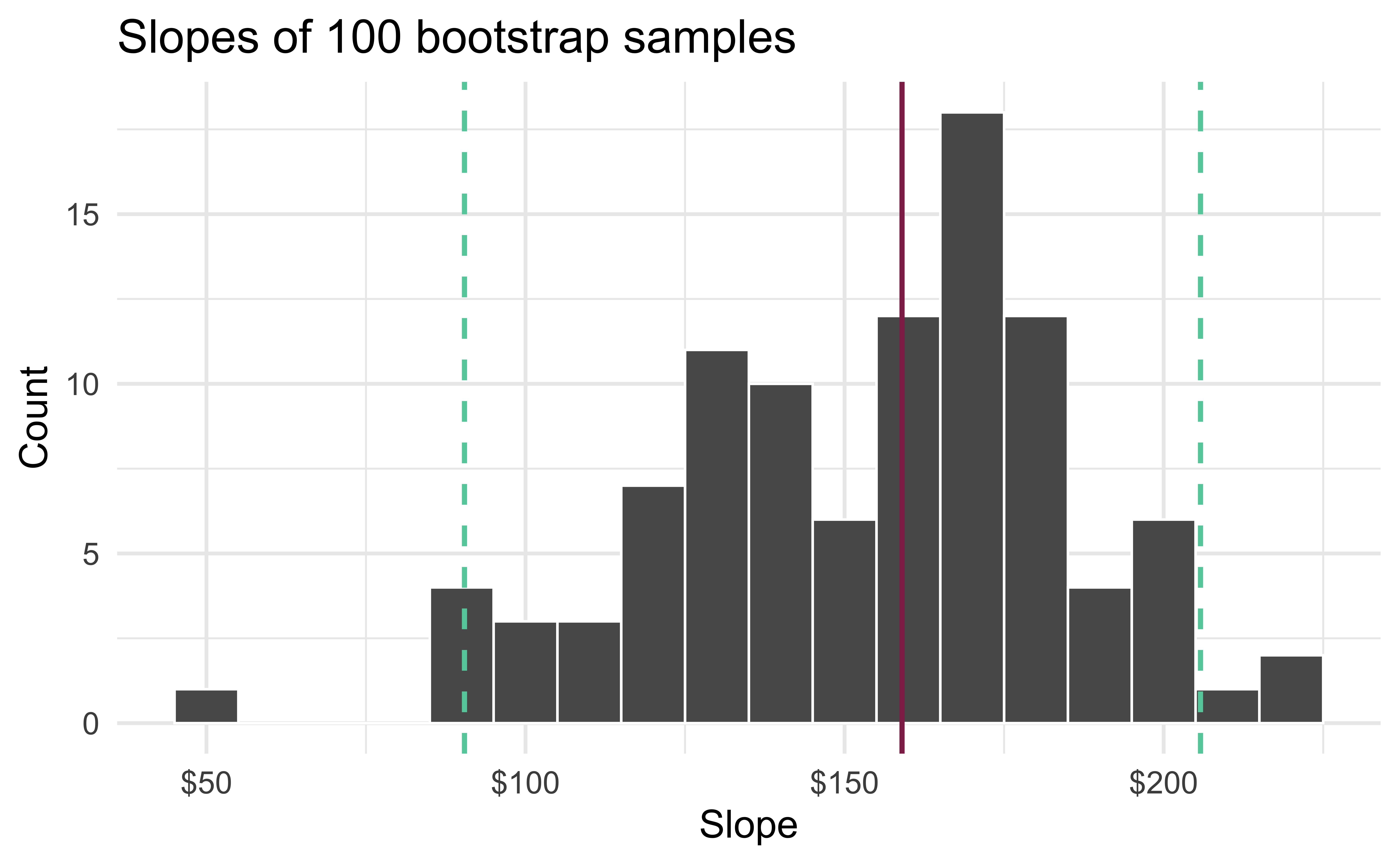
- A 95% confidence interval is bounded by the middle 95% of the bootstrap distribution
- We are 95% confident that For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $90.43 to $205.77.
Precision vs. accuracy
If we want to be very certain that we capture the population parameter, should we use a wider or a narrower interval? What drawbacks are associated with using a wider interval?

Sampling is natural

- When you taste a spoonful of soup and decide the spoonful you tasted isn’t salty enough, that’s exploratory analysis
- If you generalize and conclude that your entire soup needs salt, that’s an inference
- For your inference to be valid, the spoonful you tasted (the sample) needs to be representative of the entire pot (the population)
Statistical significance
Do the data provide sufficient evidence that \(\beta_1\) (the true slope for the population) is different from 0?
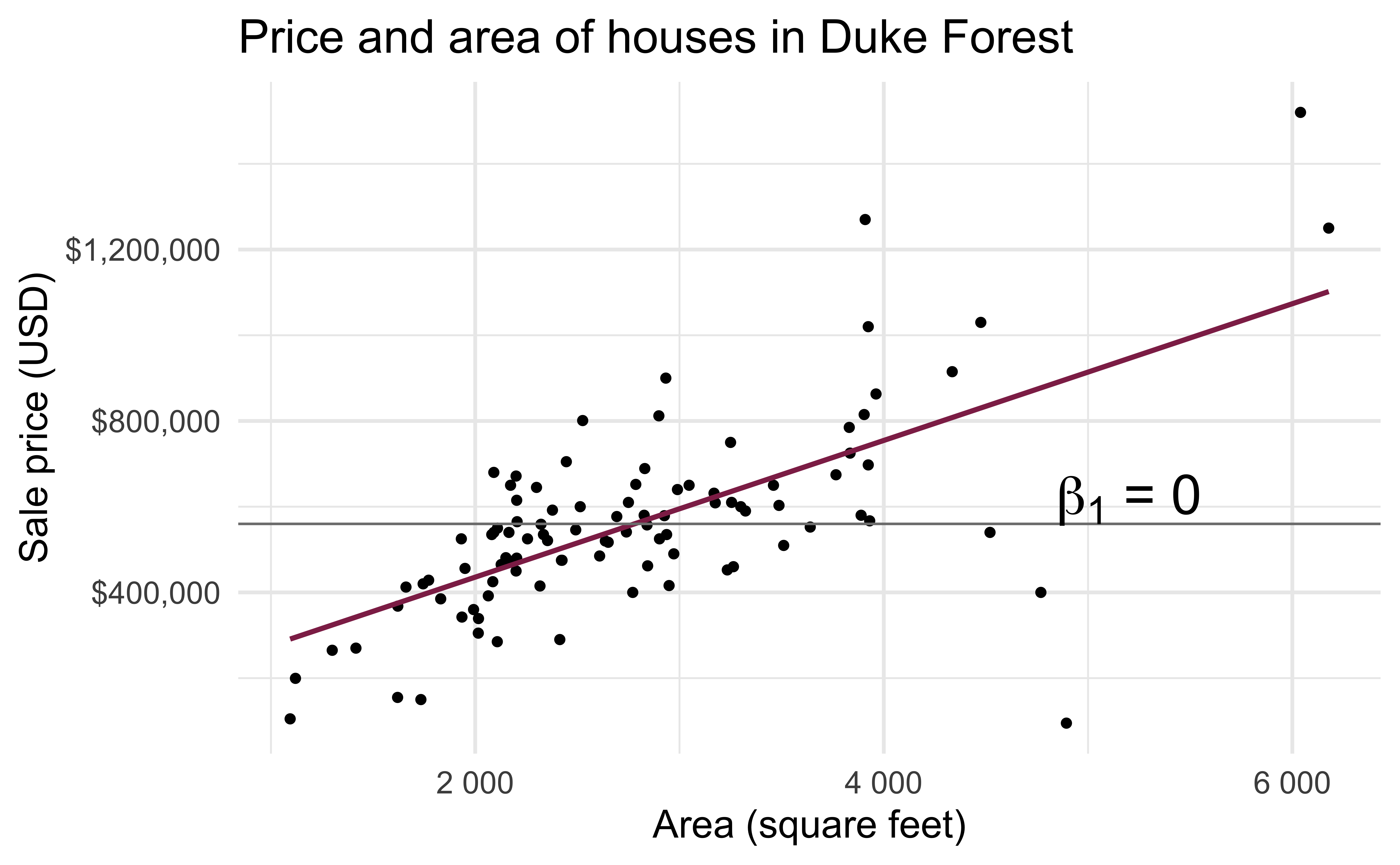
Hypothesis testing framework
- Start with a null hypothesis, \(H_0\) that represents the status quo
- Set an alternative hypothesis, \(H_A\) that represents the research question, i.e. what we’re testing for
- Conduct a hypothesis test under the assumption that the null hypothesis is true and calculate a p-value (probability of observed or more extreme outcome given that the null hypothesis is true)
- if the test results suggest that the data do not provide convincing evidence for the alternative hypothesis, stick with the null hypothesis
- if they do, then reject the null hypothesis in favor of the alternative