# load packages
library(tidyverse) # for data wrangling and visualization
library(tidymodels) # for modeling
library(openintro) # for the duke_forest dataset
library(scales) # for pretty axis labels
library(knitr) # for pretty tables
library(kableExtra) # also for pretty tables
library(patchwork) # arrange plots
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_minimal(base_size = 20))SLR: Model diagnostics
STA 210 - Spring 2022
HT: p-value
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 116652.33 | 53302.46 | 2.19 | 0.03 |
| area | 159.48 | 18.17 | 8.78 | 0.00 |
CI: Critical value
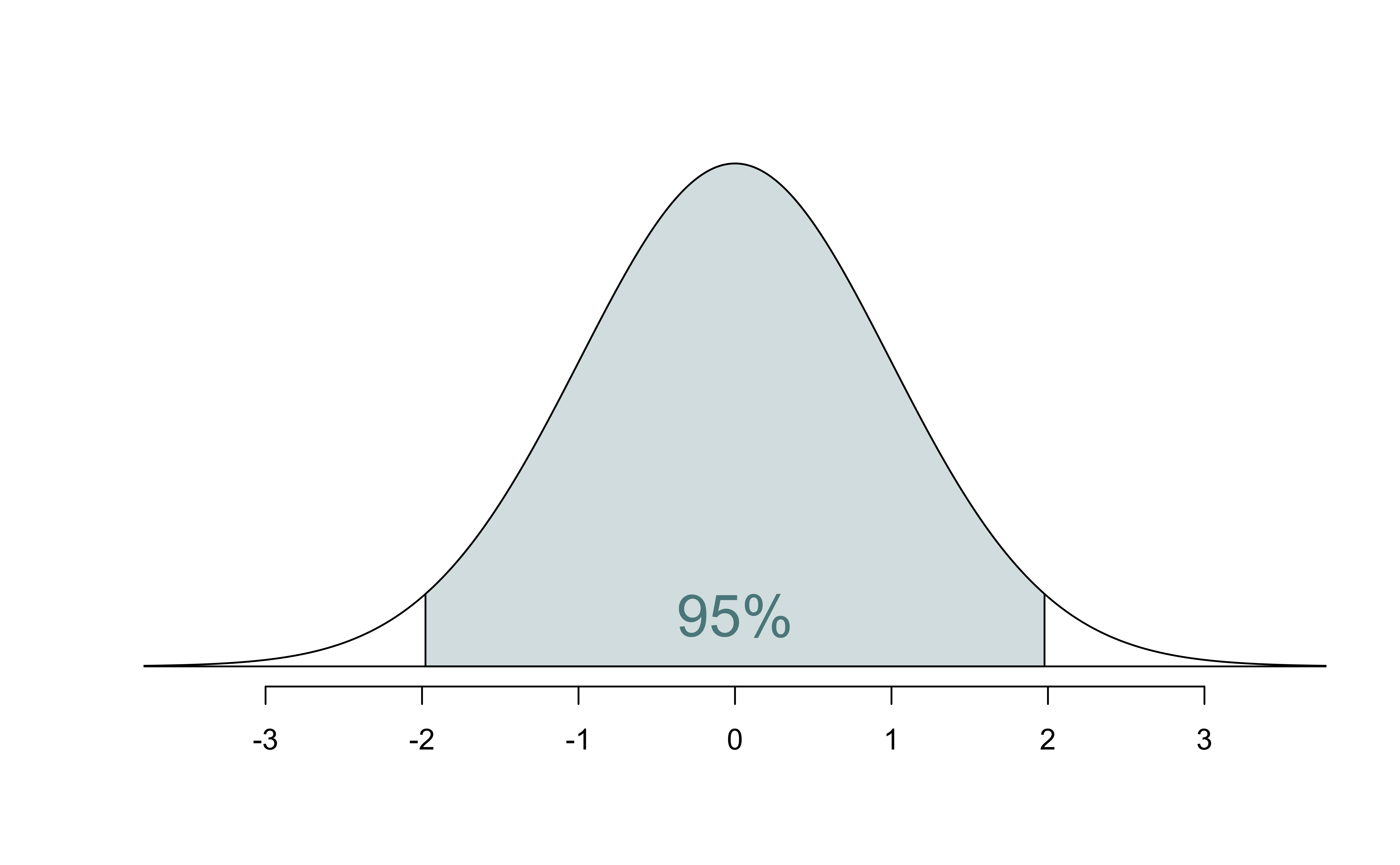
Confidence interval for predictions
- Suppose we want to answer the question “What is the predicted sale price of a Duke Forest house that is 2,800 square feet?”
- We said reporting a single estimate for the slope is not wise, and we should report a plausible range instead
- Similarly, reporting a single prediction for a new value is not wise, and we should report a plausible range instead
Comparing intervals
Extrapolation
Calculate the prediction interval for the sale price of a “tiny house” in Duke Forest that is 225 square feet.

No, thanks!
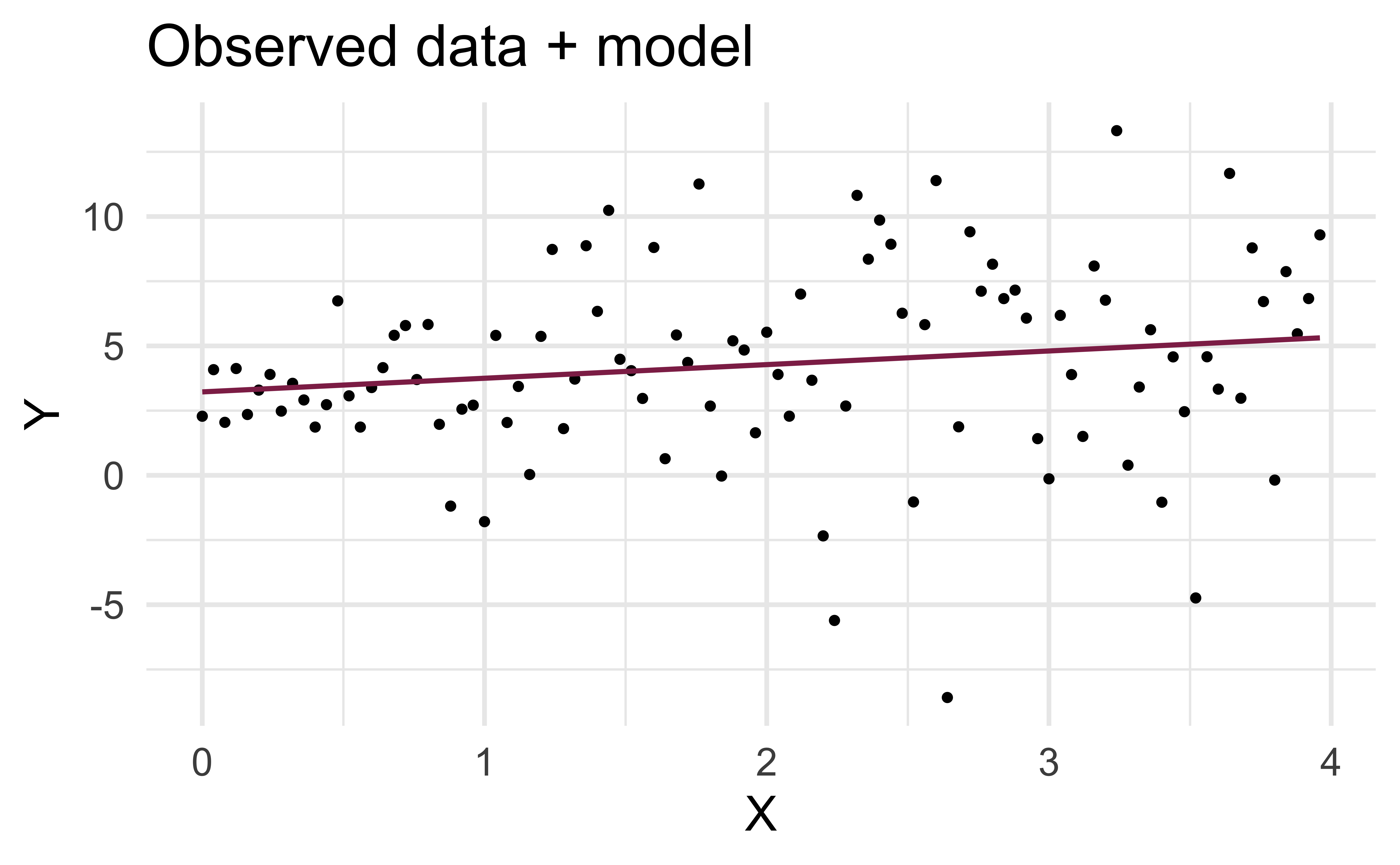
Linearity
✅ The residuals vs. fitted values plot should not show a random scatter of residuals (no distinguishable pattern or structure)
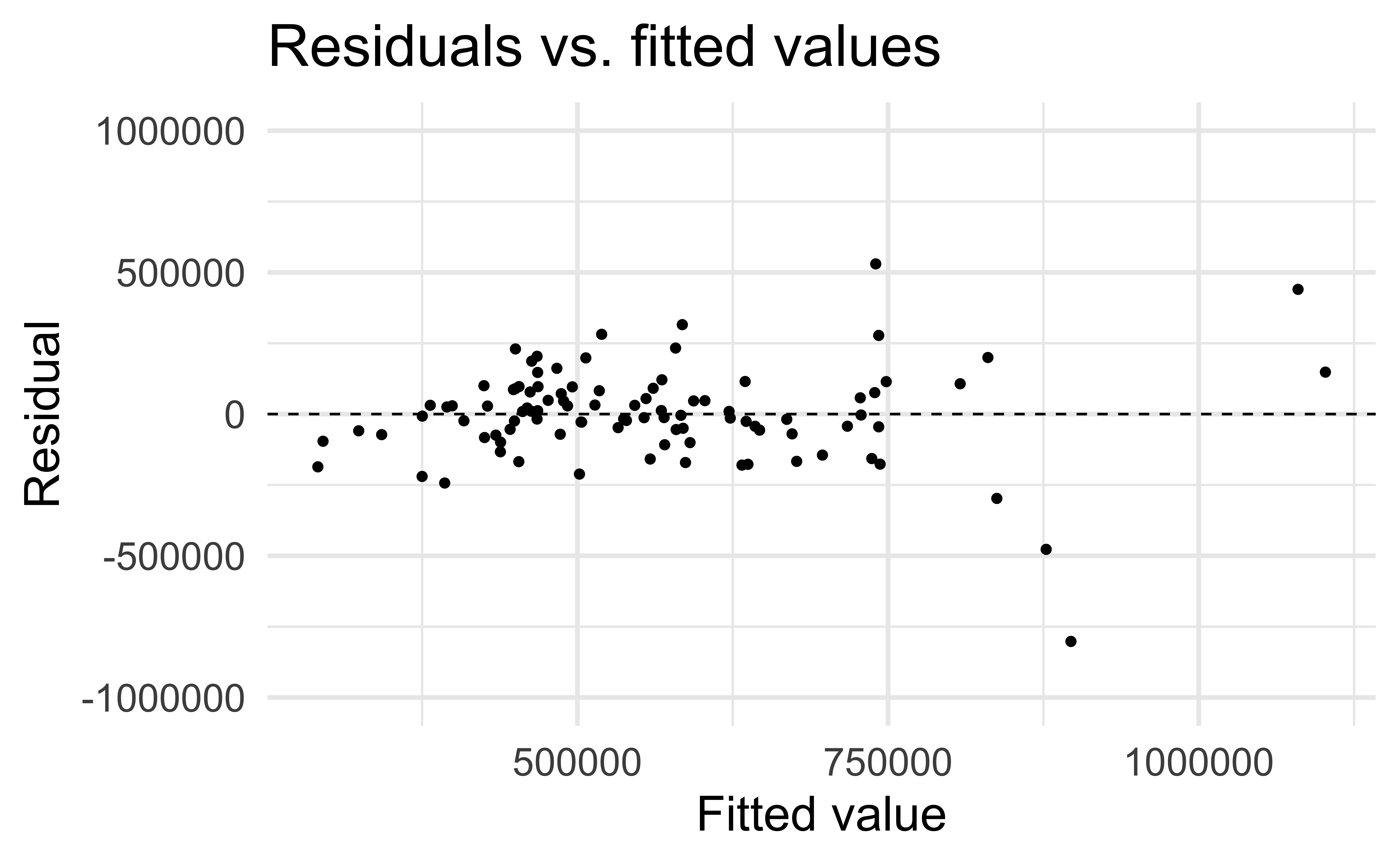
Non-linear relationships
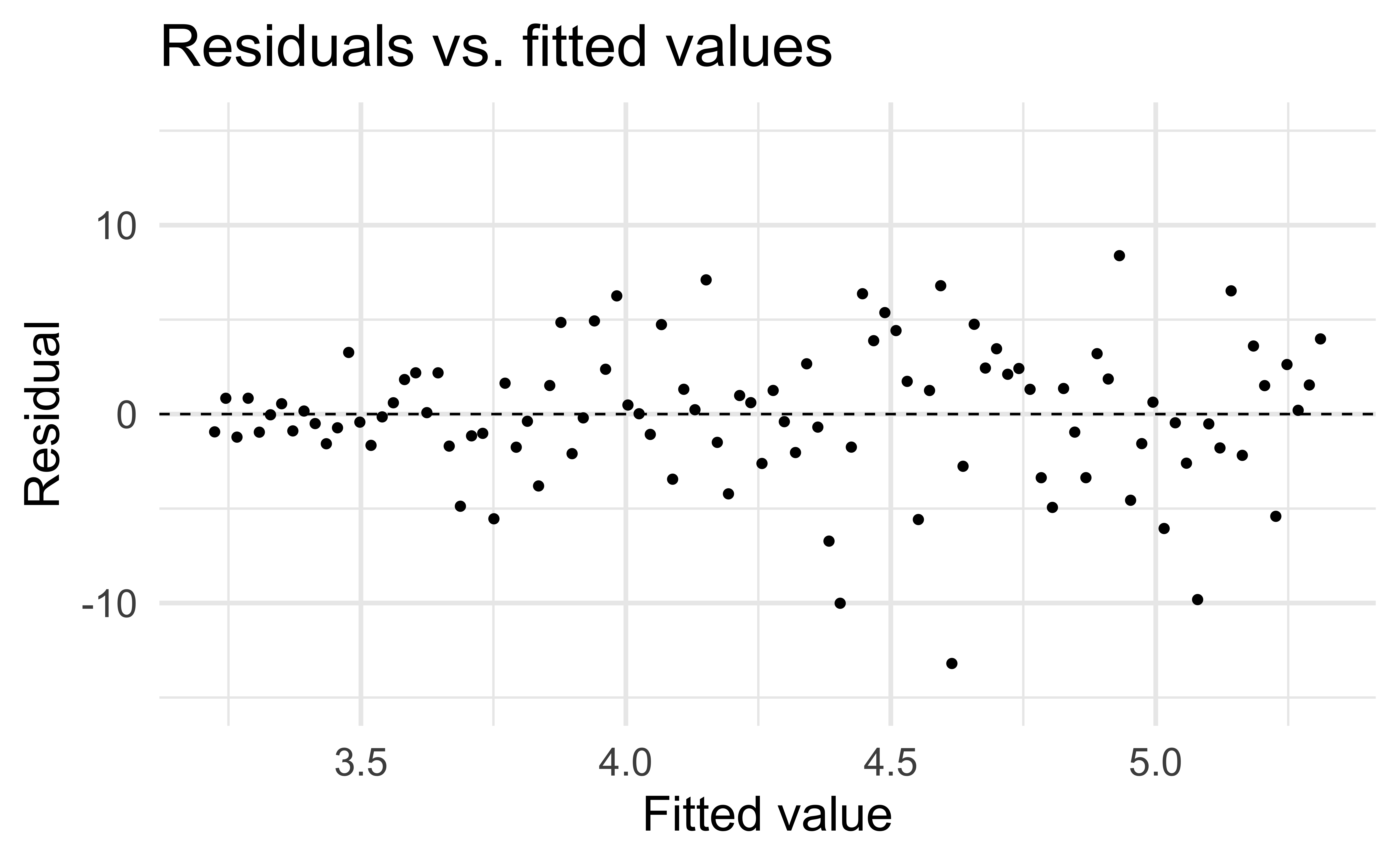
Constant variance
✅ The vertical spread of the residuals should be relatively constant across the plot
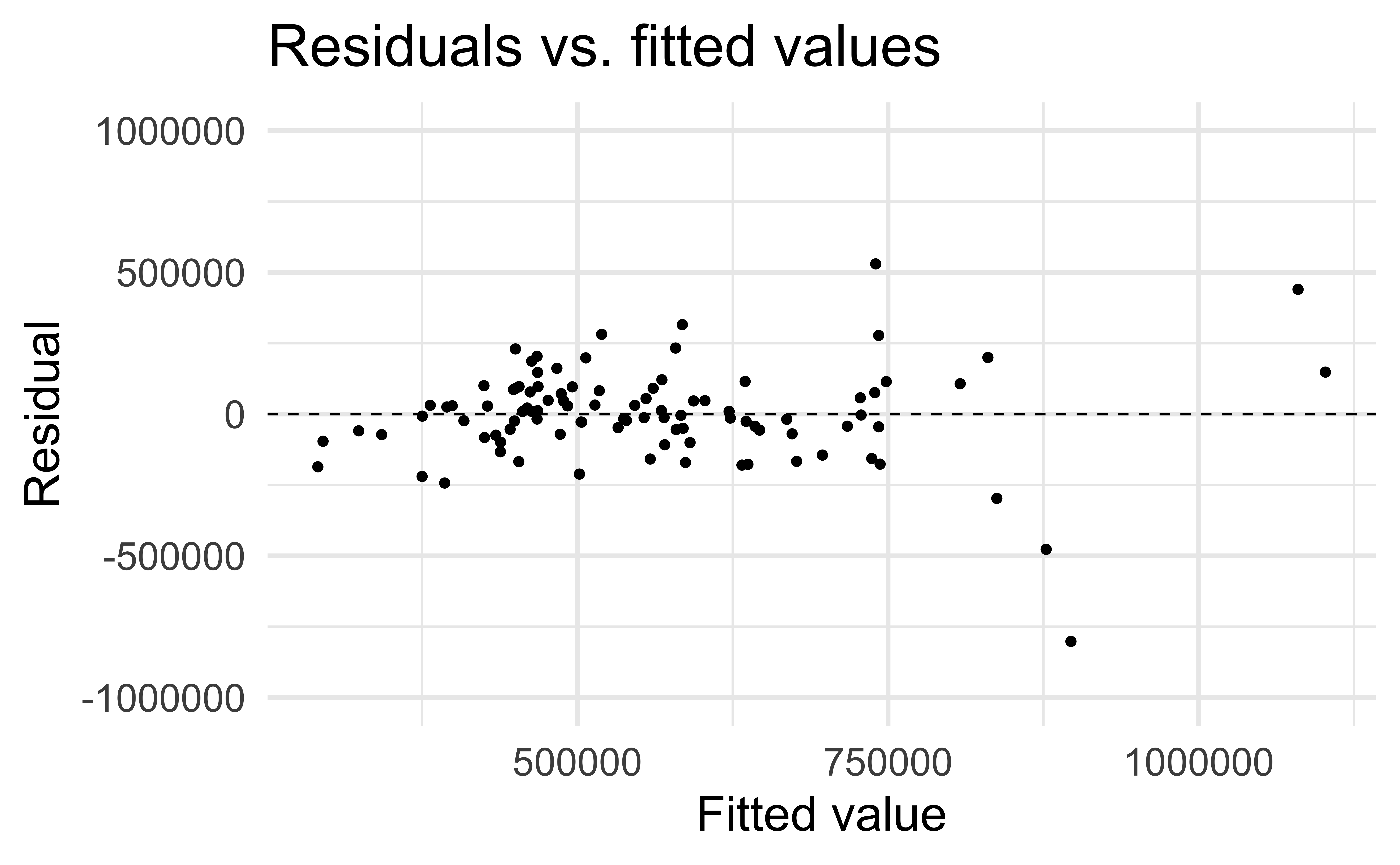
Non-constant variance
Normality
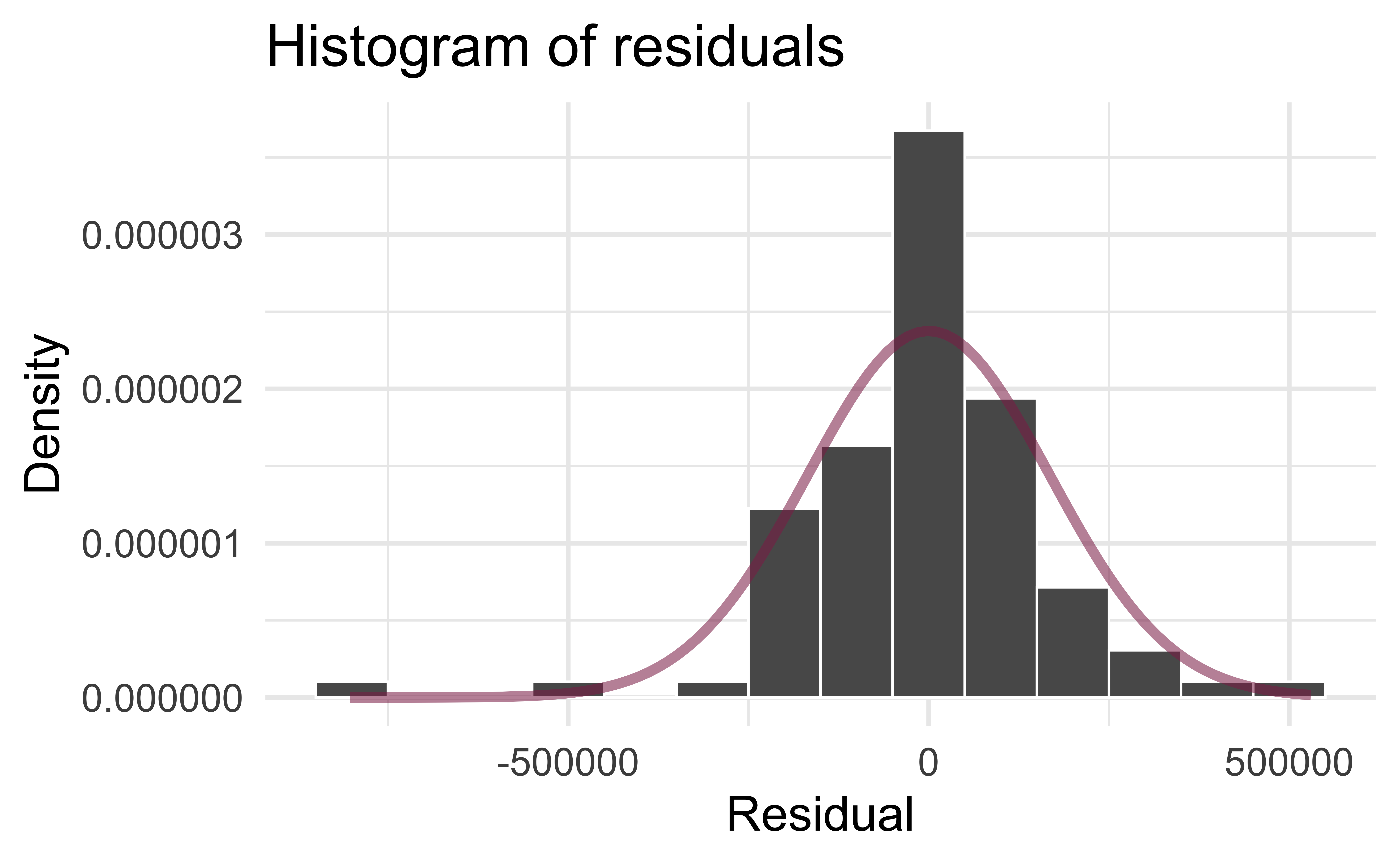
Recap
Used residual plots to check conditions for SLR:
- Linearity
- Constant variance
- Normality
- Independence
Which of these conditions are required for fitting a SLR? Which for simulation-based inference for the slope for an SLR? Which for inference with mathematical models?
03:00
![]()